Thursday, February 11, 2010
Spending money
We cut purchase orders today and rushed them through Purchasing. A Purchasing who was immensely snowed under, as can be well expected. I think final signatures get signed tomorrow.
What are we getting? Three big things:
- A new LTO4 tape library. I try not to gush lovingly at the thought, but keep in mind I've been dealing with SDLT320 and old tapes. I'm trying not to let all that space go to my head. 2 drives, 40-50 slots, fibre attached.
Made of love. No gushing, no gushing... - Fast, cheap storage. Our EVA6100 is just too expensive to keep feeding. So we're getting 8TB of 15K fast storage. We needs it, precious.
- Really cheap storage. Since the storage area networking options all came in above our stated price-point, we're ending up with direct-attached. Depending on how we slice it, between 30-35TB of it. Probably software ISCSI and all the faults inherent in the setup. We still need to dicker over software.
The last thing we have is an email archiving system. We already know what we want, but we're waiting on determination of whether or not we can spend that already ear-marked money.
Unfortunately, I'll be finding out a week from Monday. I'll be out of the office all next week. Bad timing for it, but can't be avoided.
Tuesday, February 02, 2010
Budget plans
As far as WWU is concerned, we know we'll be passed some kind of cut. We don't know the size, nor do we know what other strings may be attached to the money we do get. So we're planning for various sizes of cuts.
One thing that is definitely getting bandied about is the idea of 'sweeping' unused funds at end-of-year in order to reduce the deficits. As anyone who has ever worked in a department subject to a budget knows, the idea of having your money taken away from you for being good with your money runs counter to every bureaucratic instinct. I have yet to meet the IT department that considers themselves fully funded. My old job did that; our Fiscal year ended 12/15, which meant that we bought a lot of stuff in October and November with the funds we'd otherwise have to give back (a.k.a. "Christmas in October"). Since WWU's fiscal year starts 7/1, this means that April and May will become 'use it or lose it' time.
Sweeping funds is a great way to reduce fiscal efficiency.
In the end, what this means is that the money tree is actually producing at the moment. We have a couple of crying needs that may actually get addressed this year. It's enough to completely fix our backup environment, OR do some other things. We still have to dicker over what exactly we'll fix. The backup environment needs to be made better at least somewhat, that much I know. We have a raft of servers that fall off of cheap maintenance in May (i.e. they turn 5). We have a need for storage that costs under $5/GB but is still fast enough for 'online' storage (i.e. not SATA). As always, the needs are many, and the resources few.
At least we HAVE resources at the moment. It's a bad sign when you have to commiserate with your end-users over not being able to do cool stuff, or tell researchers they can't do that particular research since we have no where to store their data. Baaaaaad. We haven't quite gotten there yet, but we can see it from where we are.
Monday, January 25, 2010
Storage tiers
HP: What kind disk are you thinking of?
US: Oh, probably mid tier. 10K SAS would be good enough.
HP: Well, SAS only comes in 15K, and the next option down is 7.2K SATA. And really, the entire storage market is moving to SAS.
Note the lack of Fibre Channel drives. Those it seems are being depreciated. Two years ago the storage tier looked like this:
- SATA
- SAS/SCSI
- FC
- SATA
- SAS
- SSD
Back in 2003 when we bought that EVA3000 for the new 6 node NetWare cluster, clustering required shared storage. In 2003, shared storage meant one of two things:
- SCSI and SCSI disks, if using 2 nodes.
- Fibre Channel and FC Disks if using more than 2 nodes.
Now if only we had some LTO drives to back it all up.
Wednesday, January 13, 2010
NTFS and fragmentation
Today I found out why that is.
http://blogs.technet.com/askcore/archive/2009/10/16/the-four-stages-of-ntfs-file-growth.aspx
As the number of fragments increase, the MFT table has to track more and more fragments. Once the number of fragments exceeds how much can be stored directly into the MFT, it starts adding indirection layers to track the file extents.
If you have a, say, 10GB file on your backup-to-disk system, and that file has 50,000 fragments, you are absolutely at the 'stage 4' listed in that blog post. Meta-data operations on that file, such as tracking down the next extent to read from if you're doing a restore or copy, will be correspondingly more expensive than a 10GB file with 4 fragments. At the same time, attempting to write a large file that requires such massive fragmentation in turn requires a LOT more meta-data operations than a big-write on an empty filesystem.
And this, boys and girls, is why you really really really want to avoid large fragmentation on your NTFS-based backup-to-disk directories. Really.
Labels: storage
Tuesday, January 12, 2010
The costs of backup upgrades
Data Protector licenses backup-to-disk capacity by the amount of space consumed in the B2D directories. You have 15TB parked in your backup-to-disk archives, you pay for 15TB of space.
Data Protector has a few licenses for tape libraries. They have costs for each tape drive over 2, another license for libraries with between 61-250 slots, and another license for unlimited slots. There is no license for fibre-attached libraries like BackupExec and others do.
Data Protector does not license per backed up host, which is theoretically a cost savings.
When all is said and done, DP costs about $1.50 per GB in your backup to disk directories. In our case the price is a bit different since we've sunk some of those costs already, but they're pretty close to a buck fiddy per GB for Data Protector licensing alone. I haven't even gotten to physical storage costs yet, this is just licensing.
Going with an HP tape library (easy for me to spec, which is why I put it into the estimates), we can get an LTO4-based tape library that should meet our storage growth needs for the next 5 years. After adding in the needed DP licenses, the total cost per GB (uncompressed, mind) is on the order of $0.10 per GB. Holy buckets!
Calming down some, taking our current backup volume and apportioning the price of largest tape library I estimated over that backup volume and the price rises to $1.01/GB. Which means that as we grow our storage, the price-per-GB drops as less of the infrastructure is being apportioned to each GB. That's a rather shocking difference in price.
Clearly, HP really really wants you to use their de-duplication features for backup-to-disk. Unfortunately for HP, their de-duplication technology has some serious deficiencies when presented with our environment so we can't use it for our largest backup targets.
But to answer the question I started out with, what kind of mix should we have, the answer is pretty clear. As little backup-to-disk space as we can get away with. The stuff has some real benefits, as it allows us to stage backups to disk and then copy to tape during the day. But for long term storage, tape is by far the more cost-effective storage medium. By far.
Friday, September 18, 2009
The end of the line for RAID?
He has a point. Storage sizes are increasing faster than reliability figures, and the combination is a very bad thing for parity RAID. Size by itself means that large RAID sets will take a long time to rebuild. I ran into this directly with the MSA1500 I was working with a while back, where it would take a week (7 whole days!) to rework a 7TB disk-array. The same firmware also very strongly recommended against RAID5 LUNs on more than 7TB of of disks due to the non-recoverable read error rate on the SATA drives being used. RAID6 increase the durability of parity RAID, but at the cost of increased overhead.
Unfortunately, there are no clear answers. What you need really depends on what you're using it for. For very high performance storage where random I/O latency during high speed transfers are your prime performance metric, lots of cheap-ass SATA drives on randomized RAID1 pairs will probably not be enough to keep up. Data-retention archives where sequential write speeds are your prime metric is more forgiving and can take a much different storage architecture, even though it may involved an order of magnitude more space than the first option here.
One comment deserves attention, though:
The fact is that 20 years ago, a large chunk of storage was a 300MB ESDI drive for $1500, but now a large drive is hard to find above $200.Well, for large hard drives that may be true but for medium size drives I can show you many options that break the $200 barrier. 450GB FC drives? Over $200 by quite a lot. Anything SSD-Enterprise? Over $200 by a lot, and the 'large drive' segment is at an order of magnitude over that.
We're going to see some interesting storage architectures in the near future. That much is for sure.
Labels: storage
Thursday, September 10, 2009
Lemonade
Yesterday bossman gave me a 500GB Western Digital drive and I got to work restoring service. This drive has Native Command Queueing, unlike the now-dead 320GB drive. I didn't expect that to make much of a difference, but it has. My Vista VMs (undamaged) run noticibly faster now. "iostat -x" shows await times markedly lower than they were before when running multiple VMs.
NCQ isn't the kind of feature that generally speeds up desktop performance, but in this case it does. Perhaps lots of VM's are a 'server' type load afterall.
Labels: storage, virtualization
Friday, August 28, 2009
Fabric merges
Yes, this is very conservative. And I'm glad for it, since failure here would have brought down our ESX cluster and that's a very wince-worthy collection of highly visible services. But it took a lot of hacking to get the config on the switch I'm trying to merge into the fabric to be exactly right.
Labels: storage, sysadmin, virtualization
Tuesday, August 11, 2009
Changing the CommandView SSL certificate
HP's Command View EVA administration portal annoyingly overwrites the custom SSL files when it does an upgrade. So you'll have to do this every time you apply a patch or otherwise update your CV install.
- Generate a SSL certificate with the correct data.
- Extract the certificate into base-64 form (a.k.a. PEM format) in separate 'certificate' and 'private key' files.
- On your command view server overwrite the %ProgramFiles%\Hewlett-Packard\sanworks\Element Manager for StorageWorks HSV\server.cert file with the 'certificate' file
- Overwrite the %ProgramFiles%\Hewlett-Packard\sanworks\Element Manager for StorageWorks HSV\server.pkey file with the 'private key' file
- Restart the CommandView service
Friday, July 24, 2009
Migrations
Also, with Server 2008R2 being released on the 14th, that allows us to pick which OS we want to run. Microsoft just made it under the bar for us to consider that rev for fall quarter. Server 2008 R2 has a lot of new stuff in it, such as even more PowerShell (yes, it really is all that and a bag of chips) stuff, and PowerShell 2.0! "Printer Driver Isolation," should help minimize spooler faults, something I fear already even though I'm not running Windows Printing in production yet. Built in MPIO gets improvements as well, something that is very nice to have.
And yet... if we don't get it in time, we may not do it for the file serving cluster. Especially if pcounter doesn't work with the rebuilt printing paths for some reason. Won't know until we get stuff.
But once we get a delivery date for the storage pieces, we can start talking actual timelines beyond, "we hope to get it all done by fall start." Like, which weekends we'll need to block out to babysit the data migrations.
Wednesday, June 24, 2009
Why ext4 is very interesting
- Large directories. It can now handle very large directories. One source says unlimited directory sizes, and another less reliable source says sizes up to 64,000 files. This is primo for, say, a mailer. GroupWise would be able to run on this, if one was doing that.
- Extent-mapped files. More of a feature for file-systems that contain a lot of big files rather than tens of millions of 4k small files. This may be an optional feature. Even so, it replicates an XFS feature which makes ext4 a top contender for the MythTV and other linux-based PVR products. Even SD video can be 2GB/hour, HD can be a lot larger.
- Delayed allocation. Somewhat controversial, but if you have very high faith in your power environment, it can make for some nice performance gains. It allows the system to hold off on block allocation until a process either finishes writing, or triggers a dirty-cache limit, which further allows a decrease in potential file-frag and helps optimize disk I/O to some extent. Also, for highly transient files, such as mail queue files, it may allow some files to never actually hit disk between write and erase, which further increases performance. On the down side, in case of sudden power loss, delayed writes are simply lost completely.
- Persistent pre-allocation. This is a feature XFS has that allows a process to block out a defined size of disk without actually writing to it. For a PVR application, the app could pre-allocate a 1GB hunk of disk at the start of recording and be assured that it would be as contiguous as possible. Certain bittorrent clients 'preallocate' space for downloads, though some fake it by writing 4.4GB of zeros and overwriting the zeros with the true data as it comes down. This would allow such clients to truly pre-allocate space in a much more performant way.
- Online defrag. On traditional rotational media, and especially when there isn't a big chunk of storage virtualization between the server and the disk such as that provided by a modern storage array, this is much nicer. This is something else that XFS had, and ext is now picking up. Going back to the PVR again, if that recording pre-allocated 1GB of space and the recording is 2 hours long, at 2GB/hour it'll need a total of 4 GB. In theory each 1GB chunk could be on a completely diffrent part of the drive. An online defrag allows that file to be made contiguous without file-system downtime.
- SSD: A bad idea for SSD media, where you want to conserve your writes, and doesn't suffer a performance penalty for frag. Hopefully, the efstools used to make the filesystem will be smart enough to detect SSDs and set features appropriately.
- Storage Arrays: Not a good idea for extensive disk arrays like the HP EVA line. These arrays virtualize storage I/O to such an extent that file fragmentation doesn't cause the same performance problems as would a simple 6-disk RAID5 array would experience.
- Higher resolution time-stamps. This doesn't yet have much support anywhere, but it allows timestamps with nanosecond resolution. This may sound like a strange thing to put into a 'nifty features' list, but this does make me go "ooo!".
Friday, March 20, 2009
Storage that makes you think
While the bulk of the article is about how much the SSD drives blow the pants off of rotational magnetic media, the charts show how SAS performs versus SATA. As they said at the end of the article:
Our testing also shows that choosing the "cheaper but more SATA spindles" strategy only makes sense for applications that perform mostly sequential accesses. Once random access comes into play, you need two to three times more SATA drives - and there are limits to how far you can improve performance by adding spindles.Which matches my experience. SATA is great for sequential loads, but is bottom of the pack when it comes to random I/O. In a real world example, take this MSA1500CS we have. It has SATA drives in it
If you have a single disk group with 14 1TB drives in it, this gives a theoretical maximum capacity of 12.7TB (that storage industry TB vs OS TB problem again). Since you can only have LUNs as large as 2TB due to the 32-bit signed integer problem, this would mean this disk group would have to be carved into 7 LUNs. So how do you go about getting maximum performance from this set up?
You'll have to configure a logical volume on your server such that each LUN appends to the logical volume in order, and then make sure your I/O writes (or reads) sequentially across the logical volume. Since all 7 LUNs are on the same physical disks, any out-of-order arrangement of LUN on that spanned logical volume would result in semi-random I/O and throughput would drop. Striping the logical volume just ensures that every other access requires a significant drive-arm move, and would seriously drop throughput. It is for this reason that HP doesn't recommend using SATA drives in 'online' applications.
Another thing in the article that piqued my interest is there on page 11. This is where they did a test of various data/log volume combinations between SAS and SSD. The conclusion they draw is interesting, but I want to talk about it:
Transactional logs are written in a sequential and synchronous manner. Since SAS disks are capable of delivering very respectable sequential data rates, it is not surprising that replacing the SAS "log disks" with SSDs does not boost performance at all.This is true, to a point. If you have only one transaction log, this is very true. If you put multiple transaction logs on the same disk, though, SSD becomes the much better choice. They did not try this configuration. I would have liked to have seen a test like this one:
- Three Data volumes running on SAS drives
- One Log volume running on an SSD with all three database logs on it
The most transactional database in my area is probably Exchange. If we were able to move the Logs to SSD's, we very possibly could improve performance of those databases significantly. I can't prove it, but I suspect we may have some performance issues in that database.
And finally, it does raise the question of file-system journals. If I were to go out and buy a high quality 16GB SSD for my work-rig, I could use that as an external journal for my SATA-based filesystems. As it is an SSD, running multiple journals on it should be no biggie. Plus, offloading the journal-writes should make the I/O on the SATA drives just a bit more sequential and should improve speeds. But would it even be perceptible? I just don't know.
Tuesday, February 10, 2009
Bad graphs

The line across the bottom is clearly labeled "Gb/sec". Following the rule of, "big B is byte, little b is bit," this should mean gigabit, not gigabyte. Port 13 is shoving data at 45.9Mb/sec speeds, and is on a 2Gb port.
This is wrong. Port 13 is a NetWare server where I'm running a TSATEST virtual backup against a locally mounted volume. The reported data-rate was 2203 MB/Minute, or 36.7 MB/Second, or 293 Mb/sec. The difference between the reported data rate of 36.7 and the Brocade rate of 45.9 probably has to do with caching, but I'm not 100% certain of that.
More generally, I've seen these charts when I've been pushing data at 140MB/Second (a RAID0 volume, I was doing a speed test) which is over 1Gb/s. As it happens, that was the first time I'd ever seen a Fibre Channel port exceed 1Gb, so it was nifty to see. But the performance reported by the Brocade performance monitor was 140 Mb/s. Clearly, that legend on the bottom is mis-labeled.
I can't figure out why that would be, though. The fastest port we have in the system are those 4Gb ports, and their max data-rate would be 512 MB/s. A speed that wouldn't even reach "1.2" on their chart. I don't get that.
Labels: storage
Wednesday, February 04, 2009
The mystery of lsimpe.cdm
What's more, the two Windows backup-to-disk servers we've attached to the EVA4400 (and the MSA1500 for that matter) have the HP MPIO drivers installed, which are extensions of the Microsoft MPIO stack. Looking at the bandwidth chart on the fiber-channel fabric I see that these Windows servers are also doing load balancing over both of the paths. This is nifty! Also, when I last updated the XCS code on the EVA4400 both of those servers didn't even notice the controller reboots. EVEN NICER!
I want to do the same thing with NetWare. On the surface, turning on MPIO support is dead easy:
Startup.ncf file:
SET MULTI-PATH SUPPORT = ON
LOAD QL2X00.HAM SLOT=10001 /LUNS /ALLPATHS /PORTNAMESTada. Reboot, present both paths in your zoning, and issue the "list failover devices" command on the console, and you'll get a list. In theory should one go away, it'll seamlessly move over to the other.
But what it won't do is load-balance. Unfortunately, the documentation on NetWare's multi-path support is rather scanty, focusing more on configuring path failover priority. The fact that the QL2X00.HAM driver itself can do it all on its own without letting NetWare know (the "allpaths" and "portnames" options tell it to not do that and let NetWare do the work) is a strong hint that MPIO is a fairly light weight protocol.
On the support forums you'll get several references to the LSIMPE.CDM file. With interesting phrases like, "that's the multipath driver", and, "Yeah, it isn't well documented." The data on the file itself is scanty, but suggestive:
LSIMPE.CDMBut the exact details of what it does remain unclear. One thing I do know, it doesn't do the load-balancing trick.
Loaded from [C:\NWSERVER\DRIVERS\] on Feb 4, 2009 3:32:13 am
(Address Space = OS)
LSI Multipath Enhancer
Version 1.02.02 September 5, 2006
Copyright 1989-2006 Novell, Inc.
Labels: clustering, netware, novell, storage
Tuesday, February 03, 2009
More on DataProtector 6.10
One of the new features of DP6.10 is that they now have a method for pushing backup agents to Linux/HP-UX/Solaris hosts over SSH. This is very civilized of them. It uses public key and the keychain tool to make it workable.
The DP6.00 method involved tools that make me cringe. Like rlogin/rsh. These are just like telnet in that the username and password is transmitted over the wire in the clear. For several years now we've had a policy in place that states that protocols that require cleartext transmission of security principles like this are not to be used. We are not alone in this. I am very happy HP managed to get DP updated to a 21st century security posture.
Last Friday we also pointed DP at one of our larger volumes on the 6-node cluster. Backup rates from that volume blew our socks off! It pulled data at about 1600GB/Minute (a hair under 27MB/Second). For comparison, SDL320's native transfer rate (the drive we have in our tape library, which DP isn't attached to yet) is 16MB/Second. Considering the 1:1.2 to 1:1.4 compression ratios typical of this sort of file data, the max speed it can back up is still faster than tape.
The old backup software didn't even come close to these speeds, typically running in the 400MB/Min range (7MB/Sec). The difference is that the old software is using straight up TSA, where DP is using an agent. This is the difference an agent makes!
Tuesday, January 06, 2009
DataProtector 6.00 vs 6.10
No matter what you do for a copy, DataProtector will have to read all of one Disk Media (50GB by default) to do the copy. So if you multiplex 6 backups into one Disk Writer device, it'll have to look through the entire media for the slices it needs. If you're doing a session copy, it'll copy the whole session. But object copies have to be demuxed.
DP6.00 did not handle this well. Consistently, each Data Reader device consumed 100% of one CPU for a speed of about 300 MB/Minute. This blows serious chunks, and is completely unworkable for any data-migration policy framework that takes the initial backup to disk, then spools the backup to tape during daytime hours.
DP6.10 does this a lot better. CPU usage is a lot lower, it no longer pegs one CPU at 100%. Also, network speeds vary between 10-40% of GigE speeds (750 to 3000 MB/Minute), which is vastly more reasonable. DP6.10, unlike DP6.00, can actually be used for data migration policies.
Labels: backup, benchmarking, hp, storage, sysadmin
Tuesday, December 09, 2008
The price of storage
For the EVA4400, which we have filled with FATA drives, the cost is $3.03.
Suddenly, the case for Dynamic Storage Technology (formerly known as Shadow Volumes) in OES can be made in economic terms. Yowza.
The above numbers do not include backup rotation costs. Those costs can vary from $3/GB to $15/GB depending on what you're doing with the data in the backup rotation.
Why is the cost of the EVA6100 so much greater than the EVA4400?
- The EVA6100 uses 10K RPM 300GB FibreChannel disks, where the the EVA4400 uses 7.2K RPM 1TB (or is it 450GB?) FATA drives. The cost-per-gig on FC is vastly higher than it is on fibre-ATA.
- Most of the drives in the EVA6100 were purchased back when 300GB FC drives cost over $2000 each.
- The EVA6100 controller and cabinets just plain cost more than the EVA4400, because it can expand farther.
Labels: hp, novell, OES, shadowvolumes, storage
Monday, November 10, 2008
NetStorage, WebDav, and Vista
In our case you'll also need to add the CA that serves the SSL certificate that's on top of NetStorage (a.k.a. MyFiles). But, it works.
Friday, November 07, 2008
Alarming error notices
Take this example.
Without knowing what's going on, the very first line of that is panic-inducing. However, this notice was generated after I clicked the "continue deletion" button in CV-EVA after we had a disk-failure scrozz a trio of RAID0 LUNs I had been using for pure testing purposes. So, while expected, it did cause a rush to my office to see what just went wrong.
Wednesday, October 22, 2008
An old theme made new
While it doesn't say this in the specs page for that new Seagate drive, if you look on page 18 of the accompanying manual you can see the "Nonrecoverable read error" rate of the same 10^14 as I talked about two years ago. So, no improvement in reliability. However.... For their enterprise-class "Savvio" drives, they list a "Nonrecoverable Read Error" rate of 10^16 (1 in 1.25PB), which is better than the 10^15 (125TB) they were doing two years ago on their FC disks. So clearly, enterprise users are juuuust fine for large RAID5 arrays.
As I said before, the people who are going to be bitten by this will be home media servers. Also, whiteboxed homebrew servers for small/medium businesses will be at risk. So those of you who have to justify buying the really expensive disks, when there are el-cheepo 1.5TB drives out there? You can use this!
Tuesday, October 07, 2008
Erm, about the budget
In the OFM spreadsheets received today, we were stunned to find that targets had been set for higher education. Western, today, is now expected, from the sorts of measures outlined in the August 4 memorandum, to "save" $1,827,000 in the current fiscal year. (This major reduction applies across all budgets, including instructional budgets.)
Add that to the earlier number, and our total budget reduction is NOT the $176,000 representing 1% of non-instructional budgets. It is $2,003,682.
Aaaaaand...
Pardon me whilst I mutter things.Further, we have been advised to expect these reductions to be permanent; that is, to also be a part of our 2009-11 budget.
This means that it is nearly certain that we will NOT be getting any new hardware for the Novell cluster next summer. We'll have to do it on hardware we already own right now. This means I won't be able to partake of that lovely 64-bit goodness. Drat drat drat.
We're already under-funded for where we need to be, this won't help. Even with the storage arrays we just bought, in terms of total disk-space we've managed to fully commit all of it. There is no excess capacity. What's more, there is no easy way to ADD new capacity since any significant amounts will require purchasing new storage shelves.
In the intermediate term, this means that WWU will now descend into bureaucratic charge-back warfare. As service-providing departments like ours try to find ways to finance the needed growth, we'll start being hard-ass about charging for exceptional services. And they'll do it to us too. So if the College of Arts and Sciences comes to us and asks us for space to host 2TB of, say, NASA data, we'll have to bill them for it. And that cost will be a 'total cost' which will by necessity include the backup costs. In return, if we need 16 ethernet jacks added to the AC datacenter, Telecom may start billing us.
And I get a new boss Thursday. Happily, since there is overlap between outgoing and incoming they've been briefing a lot. This is to prepare the new guy for the challenges he'll face in his first few weeks flying solo. There may even be the odd phone-call for advice, we'll see.
Gonna get real interesting around here.
Thursday, October 02, 2008
MSA performance in the new config
Yes, a profligate waste of space but at least it'll be fast. It also had the added advantage of not needing to stripe in like Raid5 or Raid6 would have. This alone saved us close to two weeks flow time to get it back into service.
Another benefit to not using a parity RAID is that the MSA is no longer controller-CPU bound for I/O speeds. Right now I have a pair of writes, each effectively going to a separate controller, and the combined I/O is on the order of 100Mbs while controller CPU loads are under 80%. Also, more importantly, Average Command Latency is still in the 20-30ms range.
The limiting factor here appears to be how fast the controllers can commit I/O to the physical drives, rather than how fast the controllers can do parity-calcs. CPU not being saturated suggests this, but a "show perf physical" on the CLI shows the queue depth on individual drives:

The drives with a zero are associated with LUNs being served by the other controller, and thus not listed here. But a high queue depth is a good sign of I/O saturation on the actual drives themselves. This is encouraging to me, since it means we're finally, finally, after two years, getting the performance we need out of this device. We had to go to an active/active config with a non-parity RAID to do it, but we got it.
Labels: benchmarking, msa, storage, sysadmin
Wednesday, September 24, 2008
Fickle fortune
This puts a kink into things. This was going to be an edirectory host, so I could host my replicas on one set of servers and abuse the crap out of the non-replica application servers. I may have to dual host. Icky icky.
Tuesday, September 23, 2008
That darned 32-bit limit
I've pointed this out on an enhancement request. This being NetWare, they may not chose to fix it if it is more than a two-line fix. We'll see.
This also means that volumes over 4TB can not be effectively monitored with SNMP. Since NSS can have up to 8TB volumes on NetWare, this could potentially be a problem. We're not there yet.
Friday, September 19, 2008
Monitoring ESX datacenter volume stats
A lot of googling later I found how to turn on the SNMP daemon for an ESX host, and a script or two to publish the data I need by SNMP. It took some doing, but it ended up pretty easy to do. One new perl script, the right config for snmpd on the ESX host, setting the ESX host's security policy to permit SNMP traffic, and pointing my gathering script at the host.
The perl script that gathers the local information is very basic:
#!/usr/bin/perl -w
use strict;
my $partition = ".";
my $partmaps = ".";
my $vmfsvolume = "\Q/vmfs/volumes/$ARGV[0]\Q";
my $vmfsfriendly = $ARGV[1];
my $capRaw = 0;
my $capBlock = 0;
my $blocksize = 0;
my $freeRaw = 0;
my $freeBlock = 0;
my $freespace= "";
my $totalspace= "";
open("Y", "/usr/sbin/vmkfstools -P $vmfsvolume|");
while () {
if (/Capacity ([0-9]*).*\(([0-9]*).* ([0-9]*)\), ([0-9]*).*\(([0-9]*).*a
vail/) {
$capRaw = $1;
$capBlock = $2;
$blocksize = $3;
$freeRaw = $4;
$freeBlock = $5;
$freespace = $freeBlock;
$totalspace = $capBlock;
$blocksize = $blocksize/1024;
#print ("1 = $1\n2 = $2\n3 = $3\n4 = $4\n5 = $5\n");
print ("$vmfsfriendly\n$totalspace\n$freespace\n$blocksize\n");
}
} Then append the /etc/snmp/snmp.conf file with the following lines (in my case):
exec .1.3.6.1.4.1.6876.99999.2.0 vmfsspace /root/bin/vmfsspace.specific 48cb2cbc
-61468d50-ed1f-001cc447a19d Disk1
exec .1.3.6.1.4.1.6876.99999.2.1 vmfsspace /root/bin/vmfsspace.specific 48cb2cbc
-7aa208e8-be6b-001cc447a19d Disk2The first parameter after exec is the OID to publish. The script returns an array of values, one element per line, that are assigned to .0, .1, .2 and on up. I'm publishing the details I'm interested in, which may be different than yours. That's the 'print' line in the script.
The script itself lives in /root/bin/ since I didn't know where better to put it. It has to have execute rights for Other, though.
The big unique-ID looking number is just that, a UUID. It is the UUID assigned to the VMFS volume. The VMFS volumes are multi-mounted between each ESX host in that particular cluster, so you don't have to worry about chasing the node that has it mounted. You can find the number you want by logging in to the ESX host on the SSH console, and doing a long directory on the /vmfs/volumes folder. The friendly name of your VMFS volume is symlinked to the UUID. The UUID is what goes in to the snmp.conf file.
The last parameter ("Disk1" and "Disk2" above) is the friendly name of the volume to publish over SNMP. As you can see, I'm very creative.
These values are queried by my script and dropped into the database. Since the ESX datacenter volumes only get space consumed when we provision a new VM or take a snapshot, the graph is pretty chunky rather than curvy like the graph I linked to earlier. If VMware ever changes how the vmfstools command returns data, this script will break. But until then, it should serve me well.
Labels: stats, storage, sysadmin, virtualization
Moving storage around
Blackboard needs more space on both the SQL server and the Content server, and as the Content server is clustered it'll require an outage to manage the increase. And it'll be a long outage, as 300GB of weensy files takes a LONG time to copy. The SQL server uses plain old Basic partitions, so I don't think we can expand that partition, so we may have to do another full LUN copy which will require an outage. That has yet to be scheduled, but needs to happen before we get through much of the quarter.
Over on the EVA4400 side, I'm evacuating data off of the MSA1500cs onto the 4400. Once I'm done with that, I'm going to be:
- Rebuilding all of the Disk Arrays.
- Creating LUNs expressly for Backup-to-Disk functionality.
- Flashing the Active/Active firmware on to it, the 7.00 firmware rev.
- Get the two Backup servers installed with the right MPIO widgetry to take advantage of active/active on the MSA>
What has yet to be fully determined is exactly how we're going to use the 4400 in this scheme. I expect to get between 15-20TB of space out of the MSA once I'm done with it, and we have around 20TB on the 4400 for backup. Which is why I'd really like that 40TB license please.
Going Active/Active should do really good things for how fast the MSA can throw data at disk. As I've proven before the MSA is significantly CPU bound for I/O to parity LUNs (Raid5 and Raid6), so having another CPU in the loop should increase write throughput significantly. We couldn't do Active/Active before since you can only do Active/Active in a homogeneous OS environment, and we had Windows and NetWare pointed at the MSA (plus one non-production Linux box).
In the mean time, I watch progress bars. TB of data takes a long time to copy if you're not doing it at the block level. Which I can't.
Labels: backup, clustering, msa, storage, sysadmin
Sunday, September 14, 2008
EVA6100 upgrade a success
There was only one major hitch for the night, which meant I got to bed around 6am Saturday morning instead of 4am.
For EVA, and probably all storage systems, you present hosts to them and selectively present LUNs to those hosts. These host-settings need to have an OS configured for them, since each operating system has its own quirks for how it likes to see its storage. While the EVA6100 has a setting for 'vmware', the EVA3000 did not. Therefore, we had to use a 'custom' OS setting and a 16 digit hex string we copied off of some HP knowledge-base article. When we migrated to the EVA6100 it kept these custom settings.
Which, it would seem, don't work for the EVA6100. It caused ESX to whine in such a way that no VMs would load. It got very worrying for a while there, but thanks to an article on vmware's support site and some intuition we got it all back without data loss. I'll probably post what happened and what we did to fix it in another blog post.
The only service that didn't come up right was secure IMAP for Exchange. I don't know why it decided to not load. My only theory is that our startup sequence wasn't right. Rebooting the HubCA servers got it back.
Labels: clustering, exchange, hp, storage, sysadmin
Wednesday, September 10, 2008
That darned budget
It has been a common complaint amongst my co-workers that WWU wants enterprise level service for a SOHO budget. Especially for the Win/Novell environments. Our Solaris stuff is tied in closely to our ERP product, SCT Banner, and that gets big budget every 5 years to replace. We really need the same kind of thing for the Win/Novell side of the house, such as this disk-array replacement project we're doing right now.
The new EVAs are being paid for by Student Tech Fee, and not out of a general budget request. This is not how these devices should be funded, since the scope of this array is much wider than just student-related features. Unfortunately, STF is the only way we could get them funded, and we desperately need the new arrays. Without the new arrays, student service would be significantly impacted over the next fiscal year.
The problem is that the EVA3000 contains between 40-45% directly student-related storage. The other 55-60% is Fac/Staff storage. And yet, the EVA3000 was paid for by STF funds in 2003. Huh.
The summer of 2007 saw a Banner Upgrade Project, when the servers that support SCT Banner were upgraded. This was a quarter million dollar project and it happens every 5 years. They also got a disk-array upgrade to a pair of StorageTek (SUN, remember) arrays, DR replicated between our building and the DR site in Bond Hall. I believe they're using Solaris-level replication rather than Array-level replication.
The disk-array upgrade we're doing now got through the President's office just before the boom went down on big expensive purchases. It languished in the Purchasing department due to summer-vacation related under-staffing. I hate to think how late it would have gone had it been subjected to the added paperwork we now have to go through for any purchase over $1000. Under no circumstances could we have done it before Fall quarter. Which would have been bad, since we were too short to deal with the expected growth of storage for Fall quarter.
Now that we're going deep into the land of VMWare ESX, centralized storage-arrays are line of business. Without the STF funded arrays, we'd be stuck with "Departmental" and "Entry-level" arrays such as the much maligned MSA1500, or building our own iSCSI SAN from component parts (a DL385, with 2x 4-channel SmartArray controller cards, 8x MSA70 drive enclosures, running NetWare or Linux as an iSCSI target, with bonded GigE ports for throughput). Which would blow chunks. As it is, we're still stuck using SATA drives for certain 'online' uses, such as a pair of volumes on our NetWare cluster that are low usage but big consumers of space. Such systems are not designed for the workloads we'd have to subject them to, and are very poor performers when doing things like LUN expansions.
The EVA is exactly what we need to do what we're already doing for high-availability computing, yet is always treated as an exceptional budget request when it comes time to do anything big with it. Since these things are hella expensive, the budgetary powers-that-be balk at approving them and like to defer them for a year or two. We asked for a replacement EVA in time for last year's academic year, but the general-budget request got denied. For this year we went, IIRC, both with general-fund and STF proposals. The general fund got denied, but STF approved it. This needs to change.
By October, every person between and Governor Gregoir will be new. My boss is retiring in October. My grandboss was replaced last year, my great grand boss also has been replaced in the last year, and the University President stepped down on September 1st. Perhaps the new people will have a broader perspective on things and might permit the budget priorities to be realigned to the point that our disk-arrays are classified as the critical line-of-business investments they are.
Labels: budget, clustering, exchange, hp, linux, msa, netware, novell, OES, opinion, storage, sysadmin, virtualization
Disk-array migrations done right
We've set up the 4400 already, and as part of that we had to upgrade our CommandView version from the 4.something it was with the EVA3000 to CommandView 8. As a side effect of this, we lost licensing for the 3000 but that's OK since we're replacing that this weekend. I'm assuming the license codes for the 6100 are in the boxes the 6100 parts are in. We'll find that out Friday night, eh?
One of the OMG NICE things that comes with the new CommandView is a 60 day license for both ContinuousAccess EVA and BusinessCopy EVA. ContinuousAccess is the EVA to EVA replication software, and is the only way to go for EVA to EVA migrations. We started replicating LUNs on the 6100 to the 4400 on Monday, and they just got done replicating this morning. This way, if the upgrade process craters and we lose everything, we have a full block-level replica on the 4400. So long as we get it all done by 10/26/2008, which we should do.
On a lark we priced out what purchasing both products would cost. About $90,000, and that's with our .edu discount. That's a bit over half the price of the HARDWARE, which we had to fight tooth and nail to get approved in the first place. So. Not getting it for production.
But the 60 day license is the only way to do EVA to EVA migrations. In 5 years when the 6100 falls off of maintenance and we have to forklift replace a new EVA in, it will be ContinuousAccess EVA (eval) that we'll use to replicate the LUNs over to the new hardware. Then on migration date we'll shut everything down ("quiesce I/O"), make sure all the LUN presentations on the new array look good, break the replication groups, and rezone the old array out. Done! Should be a 30 minute outage.
Without the eval license it'd be a backup-restore migration, and that'd take a week.
Wednesday, September 03, 2008
EVA4400 + FATA
Key points I've learned:One thing I alluded to in the above is that Random Read performance is rather bad. And yes, it is. Unfortunately, I don't yet know if this is a feature of testing methodology or what, but it is worrysome enough that I'm figuring it into planning. The fastest random-read speed turned in for a 10GB file, 64KB nibbles, came to around 11 MB/s. This was on a 32-disk disk-group on a Raid5 vdisk. Random Read is the test that closest approximates file-server or database loads, so it is important.The "Same LUN" test showed that Write speeds are about half that of the single threaded test, which gives about equal total throughput to disk. The Read speeds are roughly comperable, giving a small net increase in total throughput from disk. Again, not sure why. The Random Read tests continue to perform very poorly, though total throughput in parallel is better than the single threaded test.
- The I/O controllers in the 4400 are able to efficiently handle more data than a single host can throw at it.
- The FATA drives introduce enough I/O bottlenecks that multiple disk-groups yield greater gains than a single big disk-group.
- Restripe operations do not cause anywhere near the problems they did on the MSA1500.
- The 4400 should not block-on-write the way the MSA did, so the NetWare cluster can have clustered volumes on it.
The "Different LUN, same disk-group," test showed similar results to the "Same LUN" test in that Write speeds were about half of single threaded yielding a total Write throughput that closely matches single-threaded. Read speeds saw a difference, with significant increases in Read throughput (about 25%). The Random Read test also saw significant increases in throughput, about 37%, but still is uncomfortably small at a net throughput of 11 MB/s.
The "Different LUN, different disk-group," test did show some I/O contention. For Write speeds, the two writers showed speeds that were 67% and 75% of the single-threaded speeds, yet showed a total throughput to disk of 174 MB/s. Compare that with the fasted single-threaded Write speed of 130 MB/s. Read performance was similar, with the two readers showing speeds that were 90% and 115% of the single-threaded performance. This gave an aggregate throughput of 133 MB/s, which is significantly faster than the 113 MB/s turned in by the fastest Reader test.
Adding disks to a disk-group appears to not significantly impact Write speeds, but significantly impact Read speeds. The Read speed dropped from 28 MB/s to 15 MB/s. Again, a backup-to-disk operation wouldn't notice this sort of activity. The Random Read test showed a similar reduction in performance. As Write speeds were not affected by restripe, the sort of cluster hard-locks we saw with the MSA1500 on the NetWare cluster will not occur with the EVA4400.
And finally, a word about controller CPU usage. In all of my testing I've yet to saturate a controller, even during restripe operations. It was the restripe ops that killed the MSA, and the EVA doesn't seem to block nearly as hard. Yes, read performance is dinged, but not nearly to the levels that the MSA does. This is because the EVA keeps its cache enabled during restripe-ops, unlike the MSA.
HP has done an excellent job tuning the caches for the EVA4400, which makes Write performance exceed Read performance in most cases. Unfortunately, you can't do the same reordering optimization tricks for Read access that you can for Writes, so Random Read is something of a worst-case scenario for these sorts of disks. HP's own documentation says that FATA drives should not be used for 'online' access such as file-servers or transactional databases. And it turns out they really meant that!
That said, these drives sequential write performance is excellent, making them very good candidates for Backup-to-Disk loads so long as fragmentation is constrained. The EVA4400 is what we really wanted two years ago, instead of the MSA1500.
Still no word on whether we're upgrading the EVA3000 to a EVA6100 this weekend, or next weekend. We should know by end-of-business today.
Labels: benchmarking, hp, msa, storage, sysadmin
Tuesday, September 02, 2008
EVA4400 testing
Sequential Write speed: 79,065 KB/s
Sequential Read speed: 52,107 KB/s
That's a VERY good number. The Write speed above is about the same speed as I got on the MSA1500 when running against a Raid0 volume, and this is a Raid5 volume on the 4400. The 10GB file-size test I did before this one I also watched the EVA performance on the monitoring server, and controller CPU during that time was 15-20% max. Also, it really used both controllers (thanks to MPIO).
Random Write speed: 46,427 KB/s
Random Read speed: 3,721 KB/s
Now we see why HP strongly recommends against using FATA drives for random I/O. For a file server that's 80% read I/O, it would be a very poor choice. This particular random-read test is worst-case, since a 100GB file can't be cached in RAM so this represents pure array performance. File-level caching on the server itself would greatly improve performance. The same test with a 512MB file turns in a random read number of 1,633,538 KB/s which represents serving the whole test in cache-RAM on the testing station itself.
This does suggest a few other tests:
- As above, but two 100MB files at the same time on the same LUN
- As above, but two 100MB files at the same time on different LUNs in the same Disk Group
- As above, but two 100MB files at the same time on different LUNs in different Disk Groups
Labels: benchmarking, hp, msa, storage
Friday, August 29, 2008
Storage update
And today we schlepped the whole EVA4400 to the Bond Hall datacenter.
And now I'm pounding the crap out of it to make sure it won't melt under the load we intend to put on it. These are FATA disks, which we've never used so we need to figure it out. We're not as concerned with the 6100 since that's FC disks, and they've been serving us just fine for years.
Also on the testing list, making sure MPIO works the way we expect it to.
Labels: benchmarking, storage
Wednesday, August 27, 2008
Woot!
There was some fear that the gear wouldn't get here in time for the 9/5 window. The 9/12 window has one of the key, key people needed to handle the migration in Las Vegas for VMWorld, and he won't be back until 9/21 which also screws with the 9/19 window. The 9/19 window is our last choice, since that weekend is move-in weekend and the outage will be vastly more noticeable with students around. Being able to make the 9/5 window is great! We need these so badly that if we didn't get the gear in time, we'd have probably done it 9/12 even without said key player.
The one hitch is if HP can't do 9/5-6 for some reason. Fret. Fret.
Labels: clustering, storage, sysadmin, virtualization
Monday, August 25, 2008
Dynamic partitions in Server 2008 and Cluster
Labels: clustering, microsoft, opinion, storage, sysadmin
Email sizes
This, perhaps, is not what it should be for an institution of higher-ed where research is performed. We have certain researchers on campus that routinely play with datasets larger than 10MB, sometimes significantly larger. And these researchers would like to electronically distribute these datasets to other researchers, and the easiest means of doing that by far is email. The primary reason we have mail-servers serving the (for example) chem.wwu.edu domain is to have these folk with much larger message size limits. Otherwise, these folk would have their primary email in Exchange.
The routine answer I've heard for handling really large file sizes is to use, "alternate means," to send the file. We don't have a FTP server for staff use, since we have a policy that forbids the use of unauthenticated protocols for transmitting passwords and things. We could do something like Novell does with ftp.novell.com/incoming and create a drop-box that anyone with a WWU account can read, but that's sort of a blunt-force solution and by definition half of a half-duplex method. Our researchers would like a full duplex method, and email represents that.
So what are you all using for email size limits? Do you have any 'out of band' methods (other than snail mail) for handling larger data sizes?
Tuesday, June 24, 2008
Backing up NSS, note for the future
This is handy, as HP DataProtector doesn't support NSS backup on Linux. I need to remember this.
Monday, June 16, 2008
A good article on trustees
Labels: coolsolutions, edir, netware, novell, NSS, storage, sysadmin
Wednesday, May 14, 2008
NetWare and Xen
Guidelines for using NSS in a virtual environment
Towards the bottom of this document, you get this:
Nice stuff there! The "xenblk barriers" can also have an impact on the performance of your virtualized NetWare server. If your I/O stream runs the server out of cache, performance can really suffer if barriers are non-zero. If it fits in cache, the server can reorder the I/O stream to the disks to the point that you don't notice the performance hit.Configuring Write Barrier Behavior for NetWare in a Guest Environment
Write barriers are needed for controlling I/O behavior when writing to SATA and ATA/IDE devices and disk images via the Xen I/O drivers from a guest NetWare server. This is not an issue when NetWare is handling the I/O directly on a physical server.
The XenBlk Barriers parameter for the SET command controls the behavior of XenBlk Disk I/O when NetWare is running in a virtual environment. The setting appears in the Disk category when you issue the SET command in the NetWare server console.
Valid settings for the XenBlk Barriers parameter are integer values from 0 (turn off write barriers) to 255, with a default value of 16. A non-zero value specifies the depth of the driver queue, and also controls how often a write barrier is inserted into the I/O stream. A value of 0 turns off XenBlk Barriers.
A value of 0 (no barriers) is the best setting to use when the virtual disks assigned to the guest server’s virtual machine are based on physical SCSI, Fibre Channel, or iSCSI disks (or partitions on those physical disk types) on the host server. In this configuration, disk I/O is handled so that data is not exposed to corruption in the event of power failure or host crash, so the XenBlk Barriers are not needed. If the write barriers are set to zero, disk I/O performance is noticeably improved.
Other disk types such as SATA and ATA/IDE can leave disk I/O exposed to corruption in the event of power failure or a host crash, and should use a non-zero setting for the XenBlk Barriers parameter. Non-zero settings should also be used for XenBlk Barriers when writing to Xen LVM-backed disk images and Xen file-backed disk images, regardless of the physical disk type used to store the disk images.
So, keep in mind where your disk files are! If you're using one huge XFS partition and hosting all the disks for your VM-NW systems on that, then you'll need barriers. If you're presenting a SAN LUN directly to the VM, then you'll need to "SET XENBLK BARRIERS = 0", as they're set to 16 by default. This'll give you better performance.
Labels: benchmarking, netware, novell, NSS, OES, storage, virtualization
Monday, May 12, 2008
DataProtector 6 has a problem, continued
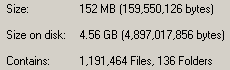
See? This is an in-progress count of one of these directories. 1.1 million files, 152MB of space consumed. That comes to an average file-size of 133 bytes. This is significantly under the 4kb block-size for this particular NTFS volume. On another server with a longer serving enhincrdb hive, the average file-size is 831 bytes. So it probably increases as the server gets older.
On the up side, these millions of weensy files won't actually consume more space for quite some time as they expand into the blocks the files are already assigned to. This means that fragmentation on this volume isn't going to be a problem for a while.
On the down side, it's going to park (in this case) 152MB of data on 4.56GB of disk space. It'll get better over time, but in the next 12 months or so it's still going to be horrendous.
This tells me two things:
- When deciding where to host the enhincrdb hive on a Windows server, format that particular volume with a 1k block size.
- If HP supported NetWare as an Enhanced Incremental Backup client, the 4kb block size of NSS would cause this hive to grow beyond all reasonable proportions.
Since it is highly likely that I'll be using DataProtector for OES2 systems, this is something I need to keep in mind.
Wednesday, May 07, 2008
DataProtecter 6 has a problem
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
- The first level is the mount point. Example: enhincrdb\F\
- The 2nd level are directories named 00-FF which contain the file state data itself
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers in most need of de-dup technology.
Wednesday, April 30, 2008
Legal processes
Our department has been pretty lucky so far. Since I started here in late 2003 this is the first Litigation Hold request we've had to deal with. We've had a few "public records requests" come through which are handled similarly, but this is the first one involving data that may be introduced under sworn testimony.
This morning we had an article pointed out to us by the Office of Finance Management at the state. WWU is a State agency, so OFM is in our chain of bureaucracy.
Case Law/Rule Changes Thrust Electronic Document Discovery into the Spotlight.
It's an older PDF, but it does give a high level view of the sorts of things we should be doing when these requests come in. One of the things that we don't have any processes for are the sequestration of held data and chain of custody preservation. We are now building those.
Guideline #4 has the phrase, "Consultants are particularly useful in this role," referring to overseeing the holding process and standing up before a court to testify that the data was handled correctly. This is very true! Trained professionals are the kind of people to know the little nuances that hostile lawyers can use to invalidate gathered evidence. Someone who has done a lot of reading and been to a few SANS classes is not that person.
Just because it is possible to self represent yourself in court as your own lawyer, doesn't make it a good idea. In fact, it generally is a very bad idea. Same thing applies to the above phrase. You want someone who knows what the heck they're doing when they climb up there onto the witness stand.
This is going to be an interesting learning experience.
Thursday, March 20, 2008
BrainShare Thursday
- Novell Open Enterprise Server 2 Interoperability with Windows and AD. All about Domain Services for Windows and Samba. Neither of which we'll ever use. No idea why I wanted to be in this session.
- Rapid Deployment of ZENworks Configuration Management. Other people around here have suggested that if we haven't moved yet, wait until at least SP3 before moving. If then. So, demotivated. Plus I was rather tired.
- Configuring Samba on OES2. CIFS will do what we need, I don't need Samba. Don't need this one. Skipped.
BASH tips and tricks. I got a lot out of it, but the developers around me were quietly derisive.
ZEN Overview and Features
Not so much with the futures, but it did explain Novell's overall ZEN strategy. It isn't a coincidence that most of Novell's recent purchases have been for ZEN products.
TUT303: OES2 Clusters, from beginning to extremes
This was great. They had a full demo rig, and they showed quite a bit in it. Including using Novell Cluster Services to migrate Xen VM's around. They STRONGLY recommended using AutoYast to set up your cluster nodes to ensure they are simply identical except for the bits you explicitly want different (hostname, IP). And also something else I've heard before, you want one LUN for each NSS Pool. Really. Plus, the presenters were rather funny. A nice cap for the day.
And tonight, Meet the Experts!
Labels: brainshare, clustering, linux, novell, NSS, OES, storage, zenworks
Friday, January 11, 2008
Disk-space over time
To show you what I'm talking about, I'm going to post a chart based on the student-home-directory data. We have three home-directory volumes for students, which run between 7000-8000 home directories on them. We load-balance by number of directories rather than least-size. The chart:
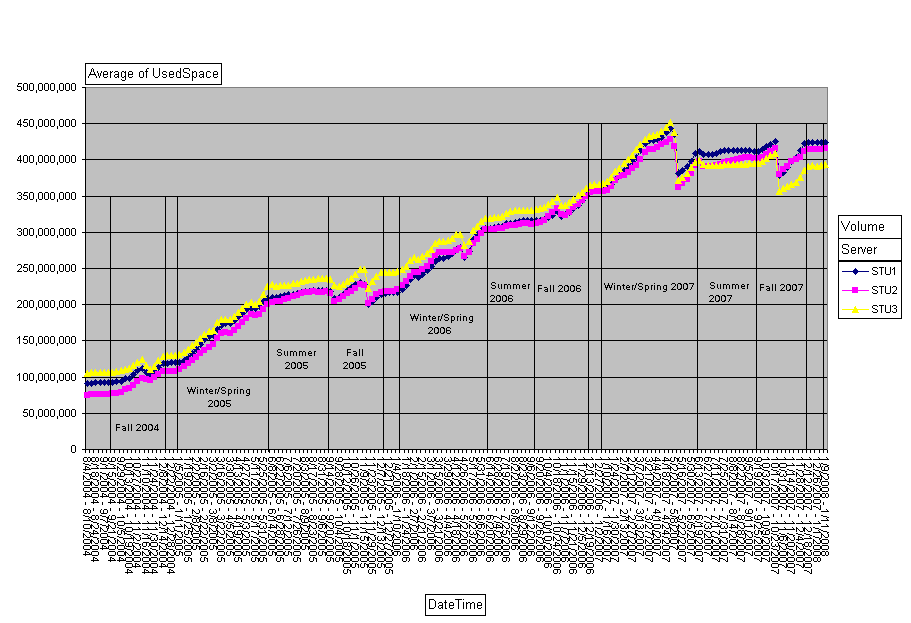
As you can see, I've marked up our quarters. Winter/Spring is one segment on this chart since Spring Break is hard to isolate on these scales. We JUST started Winter 2008, so the last dot on the chart is data from this week. If you squint in (or zoom in like I can) you can see that last dot is elevated from the dot before it, reflecting this week's classes.
There are several sudden jumps on the chart. Fall 2005. Spring 2005. Spring 2007 was a big one. Fall 2007 just as large. These reflect student delete processes. Once a student hasn't been registered for classes for a specified period of time (I don't know what it is off hand, but I think 2 terms) their account goes on the 'ineligible' list and gets purged. We do the purge once a quarter except for Summer. The Fall purge is generally the biggest in terms of numbers, but not always. Sometimes the number of students purged is so small it doesn't show on this chart.
We do get some growth over the summer, which is to be expected. The only time when classes are not in session is generally from the last half of August to the first half of September. Our printing volumes are also w-a-y down during that time.
Because the Winter purge is so tiny, Winter quarter tends to see the biggest net-gain in used disk-space. Fall quarter's net-gain sometimes comes out a wash due to the size of that purge. Yet if you look at the slopes of the lines for Fall, correcting for the purge of course, you see it matches Winter/Spring.
Somewhere in here, and I can't remember where, we increased the default student directory-quota from 200MB to 500MB. We've found Directory Quotas to be a much better method of managing student directory sizes than User Quotas. If I remember my architectures right, directory quotas are only possible because of how NSS is designed.
If you take a look at the "Last Modified Times" chart in the Volume Inventory for one of the student home-directory volumes you get another interesting picture:
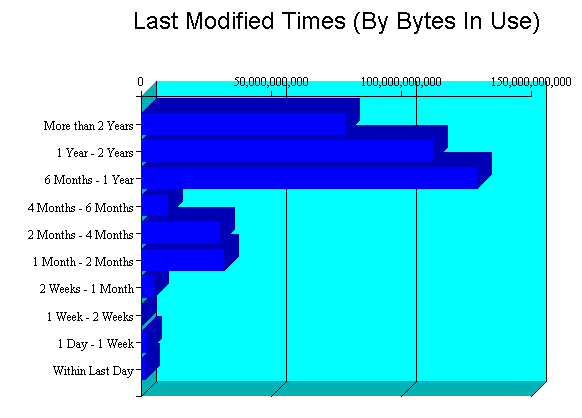
We have a big whack of data aged 12 months or newer. That said, we have non-trivial amounts of data aged 12 months or older. This represents where we'd get big savings when we move to OES2 and can use Dynamic Storage Technology (formerly known as 'shadowvolumes'). Because these are students and students only stick around for so long, we don't have a lot of stuff in the "older than 2 years" column that is very present on the Faculty/Staff volumes.
Being the 'slow, cheap,' storage device is a role well suited to the MSA1500 that has been plaguing me. If for some reason we fail to scare up funding to replace our EVA3000 with another EVA less filled-to-capacity, this could buy a couple of years of life on the EVA3000. Unfortunately, we can't go to OES2 until Novell ships an edirectory enabled AFP server for Linux, currently scheduled for late 2008 at the earliest.
Anyway, here is some insight into some of our storage challenges! Hope it has been interesting.
Monday, January 07, 2008
I/O starvation on NetWare, another update
This time when I opened the case I mentioned that we see performance problems on the backup-to-disk server, which is Windows. Which is true, when the problem occurs B2D speeds drop through the floor; last Friday a 525GB backup that normally completes in 6 hours took about 50 hours. Since I'm seeing problems on more than one operating system, clearly this is a problem with the storage device.
The first line tech agreed, and escalated. The 2nd line tech said (paraphrased):
I'm seeing a lot of parity RAID LUNs out there. This sort of RAID uses CPU on the MSA1000 controllers, so the results you're seeing are normal for this storage system.Which, if true, puts the onus of putting up with a badly behaved I/O system onto NetWare again. The tech went on to recommend RAID1 for the LUNs that need high performance when doing array operations that disable the internal cache. Which, as far as I can figure, would work. We're not bottlenecking on I/O to the physical disks, the bottleneck is CPU on the MSA1000 controller that's active. Going RAID1 on the LUNs would keep speeds very fast even when doing array operations.
That may be where we have to go with this. Unfortunately, I don't think we have 16TB of disk-drives available to fully mirror the cluster. That'll be a significant expense. So, I think we have some rethinking to do regarding what we use this device for.
Friday, December 28, 2007
NetWare and Hyperthreading, again
It has long been consensus in the support forums that, (paraphrased) "If you have hyperthreading turned on and get an I/O thread stuck on a logical process, woe be unto you."
I have a server that I've been backing up for a fellow admin in another department. This particular server has 525GB of storage to back up, so it's going to take some time. It has been vexing figuring this one out. Until today, when I finally twigged to the fact that this server has HT turned on. I turn HT off as almost the first thing I do when setting up a server, so I don't think about it when troubleshooting.
Between 1000 and 1215 today, the backup got 882MB of data. Yeah, very crappy.
At 1215 I turned off the logical processors. This is a handy feature NetWare has, and I used it in the article I linked above.
At 1222 when I checked back the backup was up to 4.0GB.
At 1417 it is now up to 71GB backed up.
The only thing that changed was me turning off the logical processors. That's it. At that rate, this server should be backed up in around 15 hours, which is a far cry from the 30+ hours it was doing before.
Turn Hyperthreading off on your NetWare servers. Just do it.
Labels: hyperthreading, netware, novell, storage
Wednesday, November 28, 2007
I/O starvation on NetWare, HP update
This morning I got a voice-mail from HP, an update for our case. Greatly summarized:
The MSA team has determined that your device is working perfectly, and can find no defects. They've referred the case to the NetWare software team.Or...
Working as designed. Fix your software. Talk to Novell.Which I'm doing. Now to see if I can light a fire on the back-channels, or if we've just made HP admit that these sorts of command latencies are part of the design and need to be engineered around in software. Highly frustrating.
Especially since I don't think I've made back-line on the Novell case yet. They're involved, but I haven't been referred to a new support engineer yet.
Labels: clustering, hp, msa, netware, novell, OES, storage, sysadmin
Wednesday, November 21, 2007
I/O starvation on NetWare
This is a problem with our cluster nodes. Our cluster nodes can seen LUNs on both the MSA1500cs and the EVA3000. The EVA is where the cluster has been housed since it started, and the MSA has taken up two low-I/O-volume volumes to make space on the EVA.
IF the MSA is in the high Avg Command Latency state, and
IF a cluster node is doing a large Write to the MSA (such as a DVD ISO image, or B2D operation),
THEN "Concurrent Disk Requests" in Monitor go north of 1000
This is a dangerous state. If this particular cluster node is housing some higher trafficked volumes, such as FacShare:, the laggy I/O is competing with regular (fast) I/O to the EVA. If this sort of mostly-Read I/O is concurrent with the above heavy Write situation it can cause the cluster node to not write to the Cluster Partition on time and trigger a poison-pill from the Split Brain Detector. In short, the storage heart-beat to the EVA (where the Cluster Partition lives) gets starved out in the face of all the writes to the laggy MSA.
Users definitely noticed when the cluster node was in such a heavy usage state. Writes and Reads took a loooong time on the LUNs hosted on the fast EVA. Our help-desk recorded several "unable to map drive" calls when the nodes were in that state, simply because a drive-mapping involves I/O and the server was too busy to do it in the scant seconds it normally does.
This is sub-optimal. This also doesn't seem to happen on Windows, but I'm not sure of that.
This is something that a very new feature in the Linux kernel could help out, that that's to introduce the concept of 'priority I/O' to the storage stack. I/O with a high priority, such as cluster heart-beats, gets serviced faster than I/O of regular priority. That could prevent SBD abends. Unfortunately, as the NetWare kernel is no longer under development and just under Maintenance, this is not likely to be ported to NetWare.
I/O starvation. This shouldn't happen, but neither should 270ms I/O command latencies.
Labels: clustering, hp, msa, netware, novell, OES, storage, sysadmin
Tuesday, September 04, 2007
Expanding the EVA
And wow does it take a while.
First I have to ungroup the disk. This can take up to two days. Then I pull the drive, and put the new one in. And regroup on top of it, which takes another up to two days. All the group/ungroup operations are competing for I/O with regular production.
Total time to add 157GB to the SAN? Looks to be 3 days and change.
We need a newer EVA.
Thursday, July 19, 2007
That darned MSA again
The setup:
- NetWare 6.5, SP5 plus patches
- EVA3000 visible
- MSA1500cs visible
- Pool in question hosted on the MSA
- Pool in question has snapshots
- Do a nss /poolrebuild on the pool
7-19-2007 9:48:22 am: COMN-3.24-1092 [nmID=A0025]The block number changes every time, and when it decides to crap out of the rebuild also changes every time. No consistency. The I/O error (20204) decodes to:
NSS-3.00-5001: Pool FACSRV2/USER2DR is being deactivated.
An I/O error (20204(zio.c[2260])) at block 36640253(file block
-36640253)(ZID 1) has compromised pool integrity.
zERR_WRITE_FAILURE 20204 /* the low level async block WRITE failed*/
Which, you know, shouldn't happen. And this error is consistent across the following changes:
- Updating the HAM driver (QL2300.HAM) from version 6.90.08 (a.k.a 6.90h) to 6.90.13 (6.90m).
- Updating the firmware on the card from 1.43 to 1.45 (I needed to do this anyway for the EVA3000 VCS upgrade next month)
- Applying the N65NSS5B patch, I had N65NSS5A on there before
I haven't thrown SP6 on there yet, as this is a WUF cluster node and this isn't intersession ;). This is one of those areas where I'm not sure who to call. Novell or HP? This is a critical error to get fixed as it impacts how we'll be replicating the EVA. It was errors similar to this, and activities similar to this, that caused all that EXCITEMENT about noon last Wednesday. That was not fun to live through, and we really really don't want to have that happen again.
Call Novell
| Good: | Bad: |
|
|
Friday, July 06, 2007
Getting creative with Blackboard
We, like all too many schools run Blackboard as the groupware product supporting our classrooms. There is an opensource product out there that also can do this, but we're not running it. That's not what this post is about.
First a wee bit of architecture. Roughly speaking, Blackboard is separated into three bits. The web server, the content server, and the database. The web-server is the classic Application Server that is what students and teachers interface with. The web server then talks with both the content server and database server. The content server is the ultimate home of all things like passed in homework. The database server glues this all together.
Due to policies, we have to keep courses in Blackboard for a certain number of quarters just in case a student challenges a grade. They may not be available to everyone, but those courses are still in the system. And so is all of the homework and assorted files associated with that class. Because of this, it is not unusual for us to have 2 years (6-7 quarters) of classes living on the content server, of which all but one quarter is essentially dead storage.
One of the problems we've had is that when it comes time to actually delete a course, it doesn't always clean up the Content associated with that course. Quite annoying.
This is a case where Dynamic Storage Technology would be great. Right now our Blackboard Content servers are a pair of Windows servers in a Windows Cluster. It struck me yesterday that this function could be fulfilled by a pair of OES2 servers in a Novell Clustering Services setup (or Heartbeat, but I don't know how to set THAT up), using Samba and DST to manage the storage. That way stuff that is accessed in the past, oh, 3 months would be on the fast EVA storage, and stuff older than 3 months would be exiled to the slow MSA storage. As the file-serving is done by way of web-servers rather than direct access, the performance hit by using Samba won't be noticable as the concurrency is well below the limit where that becomes a problem. Additionally, since all the files are owned by the same user I could use a non-NSS filesystem for even faster performance.
Hmmmm......
The problem here is that OES2 isn't out yet. Such a fantastical idea may be doable in the 2008 intersession window, but we may have other upgrades to handle there. But still, it IS an interesting idea.
Labels: blackboard, novell, OES, shadowvolumes, storage
![]()
