Tuesday, August 11, 2009
Changing the CommandView SSL certificate
One of the increasingly annoying things that IT shops have to put up with is web based administration portals using self-signed SSL certificates. Browsers are increasingly making this setup annoying, and for a good reason. Which is why I try and get these pages signed with a real key if they allow me to.
HP's Command View EVA administration portal annoyingly overwrites the custom SSL files when it does an upgrade. So you'll have to do this every time you apply a patch or otherwise update your CV install.
HP's Command View EVA administration portal annoyingly overwrites the custom SSL files when it does an upgrade. So you'll have to do this every time you apply a patch or otherwise update your CV install.
- Generate a SSL certificate with the correct data.
- Extract the certificate into base-64 form (a.k.a. PEM format) in separate 'certificate' and 'private key' files.
- On your command view server overwrite the %ProgramFiles%\Hewlett-Packard\sanworks\Element Manager for StorageWorks HSV\server.cert file with the 'certificate' file
- Overwrite the %ProgramFiles%\Hewlett-Packard\sanworks\Element Manager for StorageWorks HSV\server.pkey file with the 'private key' file
- Restart the CommandView service
Wednesday, February 11, 2009
Performance tuning Data Protector for NetWare
HP Data Protector has a client for NetWare (and OES2, but I'm not backing up any of those yet). This is proving to take a bit of TSA tuning to work out right. I haven't figured out where the problem exactly is, but I've worked around it.
The following settings are what I've got running right now, and seems to work. I may tweak later:
tsafs /readthreadsperjob=1
tsafs /readaheadthrottle=1
This seems to get around a contention issue I'm seeing with more aggressive settings, where the TSAFS memory will go the max allowed by the /cachememorythreshold setting and sit there, not passing data to the DP client. This makes backups go really long. The above setting somehow prevent this from happening.
If these prove stable, I may up the readaheadthrottle setting to see if it halts on that. This is an EVA6100 after all, so I should be able to go up to at least 18 if not 32 for that setting.
The following settings are what I've got running right now, and seems to work. I may tweak later:
tsafs /readthreadsperjob=1
tsafs /readaheadthrottle=1
This seems to get around a contention issue I'm seeing with more aggressive settings, where the TSAFS memory will go the max allowed by the /cachememorythreshold setting and sit there, not passing data to the DP client. This makes backups go really long. The above setting somehow prevent this from happening.
If these prove stable, I may up the readaheadthrottle setting to see if it halts on that. This is an EVA6100 after all, so I should be able to go up to at least 18 if not 32 for that setting.
High availability
64-bit OES provides some options to highly available file serving. Now that we've split the non-file services out of the main 6-node cluster, all that cluster is doing is NCP and some trivial other things. What kinds of things could we do with this should we get a pile of money to do whatever we want?
Disclaimer: Due to the budget crisis, it is very possible we will not be able to replace the cluster nodes when they turn 5 years old. It may be easier to justify eating the greatly increased support expenses. Won't know until we try and replace them. This is a pure fantasy exercise as a result.
The stats of the 6-node cluster are impressive:
A single server does have a few things to recommend it. By doing away with the virtual servers, all of the NCP volumes would be hosted on the same server. Right now each virtual-server/volume pair causes a new connection to each cluster node. Right now if I fail all the volumes to the same cluster node, that cluster node will legitimately have on the order of 15,000 concurrent connections. If I were to move all the volumes to a single server itself, the concurrent connection count would drop to only ~2500.
Doing that would also make one of the chief annoyances of the Vista Client for Novell much less annoying. Due to name cache expiration, if you don't look at Windows Explorer or that file dialog in the Vista client once every 10 minutes, it'll take a freaking-long time to open that window when you do. This is because the Vista client has to enumerate/resolve the addresses of each mapped drive. Because of our cluster, each user gets no less than 6 drive mappings to 6 different virtual servers. Since it takes Vista 30-60 seconds per NCP mapping to figure out the address (it has to try Windows resolution methods before going to Novell resolution methods, and unlike WinXP there is no way to reverse that order), this means a 3-5 minute pause before Windows Explorer opens.
By putting all of our volumes on the same server, it'd only pause 30-60 seconds. Still not great, but far better.
However, putting everything on a single server is not what you call "highly available". OES2 is a lot more stable now, but it still isn't to the legendary stability of NetWare 3. Heck, NetWare 6.5 isn't at that legendary stability either. Rebooting for patches takes everything down for minutes at a time. Not viable.
With a server this beefy it is quite doable to do a cluster-in-a-box by way of Xen. Lay a base of SLES10-Sp2 on it, run the Xen kernel, and create four VMs for NCS cluster nodes. Give each 64-bit VM 7.75GB of RAM for file-caching, and bam! Cluster-in-a-box, and highly available.
However, this is a pure fantasy solution, so chances are real good that if we had the money we would use VMWare ESX instead XEN for the VM. The advantage to that is that we don't have to keep the VM/Host kernel versions in lock-step, which reduces downtime. There would be some performance degradation, and clock skew would be a problem, but at least uptime would be good; no need to perform a CLUSTER DOWN when updating kernels.
Best case, we'd have two physical boxes so we can patch the VM host without having to take every VM down.
But I still find it quite interesting that I could theoretically buy a single server with the same horsepower as the six servers driving our cluster right now.
Disclaimer: Due to the budget crisis, it is very possible we will not be able to replace the cluster nodes when they turn 5 years old. It may be easier to justify eating the greatly increased support expenses. Won't know until we try and replace them. This is a pure fantasy exercise as a result.
The stats of the 6-node cluster are impressive:
- 12 P4 cores, with an average of 3GHz per core (36GHz).
- A total of 24GB of RAM
- About 7TB of active data
- HP ProLiant DL580 (4 CPU sockets)
- 4x Quad Core Xeon E7330 Processors (2.40GHz per core, 38.4GHz total)
- 24 GB of RAM
- The usual trimmings
- Total cost: No more than $16,547 for us
A single server does have a few things to recommend it. By doing away with the virtual servers, all of the NCP volumes would be hosted on the same server. Right now each virtual-server/volume pair causes a new connection to each cluster node. Right now if I fail all the volumes to the same cluster node, that cluster node will legitimately have on the order of 15,000 concurrent connections. If I were to move all the volumes to a single server itself, the concurrent connection count would drop to only ~2500.
Doing that would also make one of the chief annoyances of the Vista Client for Novell much less annoying. Due to name cache expiration, if you don't look at Windows Explorer or that file dialog in the Vista client once every 10 minutes, it'll take a freaking-long time to open that window when you do. This is because the Vista client has to enumerate/resolve the addresses of each mapped drive. Because of our cluster, each user gets no less than 6 drive mappings to 6 different virtual servers. Since it takes Vista 30-60 seconds per NCP mapping to figure out the address (it has to try Windows resolution methods before going to Novell resolution methods, and unlike WinXP there is no way to reverse that order), this means a 3-5 minute pause before Windows Explorer opens.
By putting all of our volumes on the same server, it'd only pause 30-60 seconds. Still not great, but far better.
However, putting everything on a single server is not what you call "highly available". OES2 is a lot more stable now, but it still isn't to the legendary stability of NetWare 3. Heck, NetWare 6.5 isn't at that legendary stability either. Rebooting for patches takes everything down for minutes at a time. Not viable.
With a server this beefy it is quite doable to do a cluster-in-a-box by way of Xen. Lay a base of SLES10-Sp2 on it, run the Xen kernel, and create four VMs for NCS cluster nodes. Give each 64-bit VM 7.75GB of RAM for file-caching, and bam! Cluster-in-a-box, and highly available.
However, this is a pure fantasy solution, so chances are real good that if we had the money we would use VMWare ESX instead XEN for the VM. The advantage to that is that we don't have to keep the VM/Host kernel versions in lock-step, which reduces downtime. There would be some performance degradation, and clock skew would be a problem, but at least uptime would be good; no need to perform a CLUSTER DOWN when updating kernels.
Best case, we'd have two physical boxes so we can patch the VM host without having to take every VM down.
But I still find it quite interesting that I could theoretically buy a single server with the same horsepower as the six servers driving our cluster right now.
Labels: hp, linux, netware, novell, NSS, OES, sysadmin, virtualization
Tuesday, February 03, 2009
More on DataProtector 6.10
We've had DP6.10 installed for several weeks now and have some experience with it. Yesterday I configured a Linux Installation Server so I can push agents out to Linux hosts without having to go through the truly horrendous install process that DP6.00 forced you to do when not using an Installation Server. This process taught me that DataProtector grew up in the land of UNIX, not Linux.
One of the new features of DP6.10 is that they now have a method for pushing backup agents to Linux/HP-UX/Solaris hosts over SSH. This is very civilized of them. It uses public key and the keychain tool to make it workable.
The DP6.00 method involved tools that make me cringe. Like rlogin/rsh. These are just like telnet in that the username and password is transmitted over the wire in the clear. For several years now we've had a policy in place that states that protocols that require cleartext transmission of security principles like this are not to be used. We are not alone in this. I am very happy HP managed to get DP updated to a 21st century security posture.
Last Friday we also pointed DP at one of our larger volumes on the 6-node cluster. Backup rates from that volume blew our socks off! It pulled data at about 1600GB/Minute (a hair under 27MB/Second). For comparison, SDL320's native transfer rate (the drive we have in our tape library, which DP isn't attached to yet) is 16MB/Second. Considering the 1:1.2 to 1:1.4 compression ratios typical of this sort of file data, the max speed it can back up is still faster than tape.
The old backup software didn't even come close to these speeds, typically running in the 400MB/Min range (7MB/Sec). The difference is that the old software is using straight up TSA, where DP is using an agent. This is the difference an agent makes!
One of the new features of DP6.10 is that they now have a method for pushing backup agents to Linux/HP-UX/Solaris hosts over SSH. This is very civilized of them. It uses public key and the keychain tool to make it workable.
The DP6.00 method involved tools that make me cringe. Like rlogin/rsh. These are just like telnet in that the username and password is transmitted over the wire in the clear. For several years now we've had a policy in place that states that protocols that require cleartext transmission of security principles like this are not to be used. We are not alone in this. I am very happy HP managed to get DP updated to a 21st century security posture.
Last Friday we also pointed DP at one of our larger volumes on the 6-node cluster. Backup rates from that volume blew our socks off! It pulled data at about 1600GB/Minute (a hair under 27MB/Second). For comparison, SDL320's native transfer rate (the drive we have in our tape library, which DP isn't attached to yet) is 16MB/Second. Considering the 1:1.2 to 1:1.4 compression ratios typical of this sort of file data, the max speed it can back up is still faster than tape.
The old backup software didn't even come close to these speeds, typically running in the 400MB/Min range (7MB/Sec). The difference is that the old software is using straight up TSA, where DP is using an agent. This is the difference an agent makes!
Tuesday, January 06, 2009
DataProtector 6.00 vs 6.10
A new version of HP DataProtector is out. One of the nicest new features is that they've greatly optimized the object/session copy speeds.
No matter what you do for a copy, DataProtector will have to read all of one Disk Media (50GB by default) to do the copy. So if you multiplex 6 backups into one Disk Writer device, it'll have to look through the entire media for the slices it needs. If you're doing a session copy, it'll copy the whole session. But object copies have to be demuxed.
DP6.00 did not handle this well. Consistently, each Data Reader device consumed 100% of one CPU for a speed of about 300 MB/Minute. This blows serious chunks, and is completely unworkable for any data-migration policy framework that takes the initial backup to disk, then spools the backup to tape during daytime hours.
DP6.10 does this a lot better. CPU usage is a lot lower, it no longer pegs one CPU at 100%. Also, network speeds vary between 10-40% of GigE speeds (750 to 3000 MB/Minute), which is vastly more reasonable. DP6.10, unlike DP6.00, can actually be used for data migration policies.
No matter what you do for a copy, DataProtector will have to read all of one Disk Media (50GB by default) to do the copy. So if you multiplex 6 backups into one Disk Writer device, it'll have to look through the entire media for the slices it needs. If you're doing a session copy, it'll copy the whole session. But object copies have to be demuxed.
DP6.00 did not handle this well. Consistently, each Data Reader device consumed 100% of one CPU for a speed of about 300 MB/Minute. This blows serious chunks, and is completely unworkable for any data-migration policy framework that takes the initial backup to disk, then spools the backup to tape during daytime hours.
DP6.10 does this a lot better. CPU usage is a lot lower, it no longer pegs one CPU at 100%. Also, network speeds vary between 10-40% of GigE speeds (750 to 3000 MB/Minute), which is vastly more reasonable. DP6.10, unlike DP6.00, can actually be used for data migration policies.
Labels: backup, benchmarking, hp, storage, sysadmin
Tuesday, December 09, 2008
The price of storage
I've had cause to do the math lately, which I'll spare you :). But as of the best numbers I have, the cost of 1GB of space on the EVA6100 is about $16.22. Probably more, since this 6100 was created out of the carcass of an EVA3000, and I don't know what percentage of parts from the old 3000 are still in the 6100 and thus can't apportion the costs right.
For the EVA4400, which we have filled with FATA drives, the cost is $3.03.
Suddenly, the case for Dynamic Storage Technology (formerly known as Shadow Volumes) in OES can be made in economic terms. Yowza.
The above numbers do not include backup rotation costs. Those costs can vary from $3/GB to $15/GB depending on what you're doing with the data in the backup rotation.
Why is the cost of the EVA6100 so much greater than the EVA4400?
For the EVA4400, which we have filled with FATA drives, the cost is $3.03.
Suddenly, the case for Dynamic Storage Technology (formerly known as Shadow Volumes) in OES can be made in economic terms. Yowza.
The above numbers do not include backup rotation costs. Those costs can vary from $3/GB to $15/GB depending on what you're doing with the data in the backup rotation.
Why is the cost of the EVA6100 so much greater than the EVA4400?
- The EVA6100 uses 10K RPM 300GB FibreChannel disks, where the the EVA4400 uses 7.2K RPM 1TB (or is it 450GB?) FATA drives. The cost-per-gig on FC is vastly higher than it is on fibre-ATA.
- Most of the drives in the EVA6100 were purchased back when 300GB FC drives cost over $2000 each.
- The EVA6100 controller and cabinets just plain cost more than the EVA4400, because it can expand farther.
Labels: hp, novell, OES, shadowvolumes, storage
Friday, November 07, 2008
Alarming error notices
CommandView EVA can throw some alarming notices to the unwary.
Take this example.
Without knowing what's going on, the very first line of that is panic-inducing. However, this notice was generated after I clicked the "continue deletion" button in CV-EVA after we had a disk-failure scrozz a trio of RAID0 LUNs I had been using for pure testing purposes. So, while expected, it did cause a rush to my office to see what just went wrong.
Take this example.
Without knowing what's going on, the very first line of that is panic-inducing. However, this notice was generated after I clicked the "continue deletion" button in CV-EVA after we had a disk-failure scrozz a trio of RAID0 LUNs I had been using for pure testing purposes. So, while expected, it did cause a rush to my office to see what just went wrong.
Sunday, September 14, 2008
EVA6100 upgrade a success
Friday night four HP tech arrived to put together the EVA6100 from a pile of parts and the existing EVA3000. It took them 5 hours to get it to the point where we could power-on and see if all of our data was still there (it was, yay), and a few hours after that on our behalf to put everything back together.
There was only one major hitch for the night, which meant I got to bed around 6am Saturday morning instead of 4am.
For EVA, and probably all storage systems, you present hosts to them and selectively present LUNs to those hosts. These host-settings need to have an OS configured for them, since each operating system has its own quirks for how it likes to see its storage. While the EVA6100 has a setting for 'vmware', the EVA3000 did not. Therefore, we had to use a 'custom' OS setting and a 16 digit hex string we copied off of some HP knowledge-base article. When we migrated to the EVA6100 it kept these custom settings.
Which, it would seem, don't work for the EVA6100. It caused ESX to whine in such a way that no VMs would load. It got very worrying for a while there, but thanks to an article on vmware's support site and some intuition we got it all back without data loss. I'll probably post what happened and what we did to fix it in another blog post.
The only service that didn't come up right was secure IMAP for Exchange. I don't know why it decided to not load. My only theory is that our startup sequence wasn't right. Rebooting the HubCA servers got it back.
There was only one major hitch for the night, which meant I got to bed around 6am Saturday morning instead of 4am.
For EVA, and probably all storage systems, you present hosts to them and selectively present LUNs to those hosts. These host-settings need to have an OS configured for them, since each operating system has its own quirks for how it likes to see its storage. While the EVA6100 has a setting for 'vmware', the EVA3000 did not. Therefore, we had to use a 'custom' OS setting and a 16 digit hex string we copied off of some HP knowledge-base article. When we migrated to the EVA6100 it kept these custom settings.
Which, it would seem, don't work for the EVA6100. It caused ESX to whine in such a way that no VMs would load. It got very worrying for a while there, but thanks to an article on vmware's support site and some intuition we got it all back without data loss. I'll probably post what happened and what we did to fix it in another blog post.
The only service that didn't come up right was secure IMAP for Exchange. I don't know why it decided to not load. My only theory is that our startup sequence wasn't right. Rebooting the HubCA servers got it back.
Labels: clustering, exchange, hp, storage, sysadmin
Wednesday, September 10, 2008
That darned budget
This is where I whine about not having enough money.
It has been a common complaint amongst my co-workers that WWU wants enterprise level service for a SOHO budget. Especially for the Win/Novell environments. Our Solaris stuff is tied in closely to our ERP product, SCT Banner, and that gets big budget every 5 years to replace. We really need the same kind of thing for the Win/Novell side of the house, such as this disk-array replacement project we're doing right now.
The new EVAs are being paid for by Student Tech Fee, and not out of a general budget request. This is not how these devices should be funded, since the scope of this array is much wider than just student-related features. Unfortunately, STF is the only way we could get them funded, and we desperately need the new arrays. Without the new arrays, student service would be significantly impacted over the next fiscal year.
The problem is that the EVA3000 contains between 40-45% directly student-related storage. The other 55-60% is Fac/Staff storage. And yet, the EVA3000 was paid for by STF funds in 2003. Huh.
The summer of 2007 saw a Banner Upgrade Project, when the servers that support SCT Banner were upgraded. This was a quarter million dollar project and it happens every 5 years. They also got a disk-array upgrade to a pair of StorageTek (SUN, remember) arrays, DR replicated between our building and the DR site in Bond Hall. I believe they're using Solaris-level replication rather than Array-level replication.
The disk-array upgrade we're doing now got through the President's office just before the boom went down on big expensive purchases. It languished in the Purchasing department due to summer-vacation related under-staffing. I hate to think how late it would have gone had it been subjected to the added paperwork we now have to go through for any purchase over $1000. Under no circumstances could we have done it before Fall quarter. Which would have been bad, since we were too short to deal with the expected growth of storage for Fall quarter.
Now that we're going deep into the land of VMWare ESX, centralized storage-arrays are line of business. Without the STF funded arrays, we'd be stuck with "Departmental" and "Entry-level" arrays such as the much maligned MSA1500, or building our own iSCSI SAN from component parts (a DL385, with 2x 4-channel SmartArray controller cards, 8x MSA70 drive enclosures, running NetWare or Linux as an iSCSI target, with bonded GigE ports for throughput). Which would blow chunks. As it is, we're still stuck using SATA drives for certain 'online' uses, such as a pair of volumes on our NetWare cluster that are low usage but big consumers of space. Such systems are not designed for the workloads we'd have to subject them to, and are very poor performers when doing things like LUN expansions.
The EVA is exactly what we need to do what we're already doing for high-availability computing, yet is always treated as an exceptional budget request when it comes time to do anything big with it. Since these things are hella expensive, the budgetary powers-that-be balk at approving them and like to defer them for a year or two. We asked for a replacement EVA in time for last year's academic year, but the general-budget request got denied. For this year we went, IIRC, both with general-fund and STF proposals. The general fund got denied, but STF approved it. This needs to change.
By October, every person between and Governor Gregoir will be new. My boss is retiring in October. My grandboss was replaced last year, my great grand boss also has been replaced in the last year, and the University President stepped down on September 1st. Perhaps the new people will have a broader perspective on things and might permit the budget priorities to be realigned to the point that our disk-arrays are classified as the critical line-of-business investments they are.
It has been a common complaint amongst my co-workers that WWU wants enterprise level service for a SOHO budget. Especially for the Win/Novell environments. Our Solaris stuff is tied in closely to our ERP product, SCT Banner, and that gets big budget every 5 years to replace. We really need the same kind of thing for the Win/Novell side of the house, such as this disk-array replacement project we're doing right now.
The new EVAs are being paid for by Student Tech Fee, and not out of a general budget request. This is not how these devices should be funded, since the scope of this array is much wider than just student-related features. Unfortunately, STF is the only way we could get them funded, and we desperately need the new arrays. Without the new arrays, student service would be significantly impacted over the next fiscal year.
The problem is that the EVA3000 contains between 40-45% directly student-related storage. The other 55-60% is Fac/Staff storage. And yet, the EVA3000 was paid for by STF funds in 2003. Huh.
The summer of 2007 saw a Banner Upgrade Project, when the servers that support SCT Banner were upgraded. This was a quarter million dollar project and it happens every 5 years. They also got a disk-array upgrade to a pair of StorageTek (SUN, remember) arrays, DR replicated between our building and the DR site in Bond Hall. I believe they're using Solaris-level replication rather than Array-level replication.
The disk-array upgrade we're doing now got through the President's office just before the boom went down on big expensive purchases. It languished in the Purchasing department due to summer-vacation related under-staffing. I hate to think how late it would have gone had it been subjected to the added paperwork we now have to go through for any purchase over $1000. Under no circumstances could we have done it before Fall quarter. Which would have been bad, since we were too short to deal with the expected growth of storage for Fall quarter.
Now that we're going deep into the land of VMWare ESX, centralized storage-arrays are line of business. Without the STF funded arrays, we'd be stuck with "Departmental" and "Entry-level" arrays such as the much maligned MSA1500, or building our own iSCSI SAN from component parts (a DL385, with 2x 4-channel SmartArray controller cards, 8x MSA70 drive enclosures, running NetWare or Linux as an iSCSI target, with bonded GigE ports for throughput). Which would blow chunks. As it is, we're still stuck using SATA drives for certain 'online' uses, such as a pair of volumes on our NetWare cluster that are low usage but big consumers of space. Such systems are not designed for the workloads we'd have to subject them to, and are very poor performers when doing things like LUN expansions.
The EVA is exactly what we need to do what we're already doing for high-availability computing, yet is always treated as an exceptional budget request when it comes time to do anything big with it. Since these things are hella expensive, the budgetary powers-that-be balk at approving them and like to defer them for a year or two. We asked for a replacement EVA in time for last year's academic year, but the general-budget request got denied. For this year we went, IIRC, both with general-fund and STF proposals. The general fund got denied, but STF approved it. This needs to change.
By October, every person between and Governor Gregoir will be new. My boss is retiring in October. My grandboss was replaced last year, my great grand boss also has been replaced in the last year, and the University President stepped down on September 1st. Perhaps the new people will have a broader perspective on things and might permit the budget priorities to be realigned to the point that our disk-arrays are classified as the critical line-of-business investments they are.
Labels: budget, clustering, exchange, hp, linux, msa, netware, novell, OES, opinion, storage, sysadmin, virtualization
Disk-array migrations done right
We have two new HP EVA systems. An EVA4400 with FATA drives that we'll be putting into our DR datacenter in Bond Hall, and upgrading our EVA3000 into an EVA6100 + 2 new enclosures. The 4400 is a brand new device, so is sitting idle right now (officially). It will be replacing the MSA1500 we purchased two years ago, and will fulfill the duties the MSA should have been doing but is too stupid to do.
We've set up the 4400 already, and as part of that we had to upgrade our CommandView version from the 4.something it was with the EVA3000 to CommandView 8. As a side effect of this, we lost licensing for the 3000 but that's OK since we're replacing that this weekend. I'm assuming the license codes for the 6100 are in the boxes the 6100 parts are in. We'll find that out Friday night, eh?
One of the OMG NICE things that comes with the new CommandView is a 60 day license for both ContinuousAccess EVA and BusinessCopy EVA. ContinuousAccess is the EVA to EVA replication software, and is the only way to go for EVA to EVA migrations. We started replicating LUNs on the 6100 to the 4400 on Monday, and they just got done replicating this morning. This way, if the upgrade process craters and we lose everything, we have a full block-level replica on the 4400. So long as we get it all done by 10/26/2008, which we should do.
On a lark we priced out what purchasing both products would cost. About $90,000, and that's with our .edu discount. That's a bit over half the price of the HARDWARE, which we had to fight tooth and nail to get approved in the first place. So. Not getting it for production.
But the 60 day license is the only way to do EVA to EVA migrations. In 5 years when the 6100 falls off of maintenance and we have to forklift replace a new EVA in, it will be ContinuousAccess EVA (eval) that we'll use to replicate the LUNs over to the new hardware. Then on migration date we'll shut everything down ("quiesce I/O"), make sure all the LUN presentations on the new array look good, break the replication groups, and rezone the old array out. Done! Should be a 30 minute outage.
Without the eval license it'd be a backup-restore migration, and that'd take a week.
We've set up the 4400 already, and as part of that we had to upgrade our CommandView version from the 4.something it was with the EVA3000 to CommandView 8. As a side effect of this, we lost licensing for the 3000 but that's OK since we're replacing that this weekend. I'm assuming the license codes for the 6100 are in the boxes the 6100 parts are in. We'll find that out Friday night, eh?
One of the OMG NICE things that comes with the new CommandView is a 60 day license for both ContinuousAccess EVA and BusinessCopy EVA. ContinuousAccess is the EVA to EVA replication software, and is the only way to go for EVA to EVA migrations. We started replicating LUNs on the 6100 to the 4400 on Monday, and they just got done replicating this morning. This way, if the upgrade process craters and we lose everything, we have a full block-level replica on the 4400. So long as we get it all done by 10/26/2008, which we should do.
On a lark we priced out what purchasing both products would cost. About $90,000, and that's with our .edu discount. That's a bit over half the price of the HARDWARE, which we had to fight tooth and nail to get approved in the first place. So. Not getting it for production.
But the 60 day license is the only way to do EVA to EVA migrations. In 5 years when the 6100 falls off of maintenance and we have to forklift replace a new EVA in, it will be ContinuousAccess EVA (eval) that we'll use to replicate the LUNs over to the new hardware. Then on migration date we'll shut everything down ("quiesce I/O"), make sure all the LUN presentations on the new array look good, break the replication groups, and rezone the old array out. Done! Should be a 30 minute outage.
Without the eval license it'd be a backup-restore migration, and that'd take a week.
Wednesday, September 03, 2008
EVA4400 + FATA
Some edited excerpts of internal reports I've generated over the last (looks at watch) week. The referenced testing operations involve either a single stream of writes, or two streams of writes in various configurations:
HP has done an excellent job tuning the caches for the EVA4400, which makes Write performance exceed Read performance in most cases. Unfortunately, you can't do the same reordering optimization tricks for Read access that you can for Writes, so Random Read is something of a worst-case scenario for these sorts of disks. HP's own documentation says that FATA drives should not be used for 'online' access such as file-servers or transactional databases. And it turns out they really meant that!
That said, these drives sequential write performance is excellent, making them very good candidates for Backup-to-Disk loads so long as fragmentation is constrained. The EVA4400 is what we really wanted two years ago, instead of the MSA1500.
Still no word on whether we're upgrading the EVA3000 to a EVA6100 this weekend, or next weekend. We should know by end-of-business today.
Key points I've learned:One thing I alluded to in the above is that Random Read performance is rather bad. And yes, it is. Unfortunately, I don't yet know if this is a feature of testing methodology or what, but it is worrysome enough that I'm figuring it into planning. The fastest random-read speed turned in for a 10GB file, 64KB nibbles, came to around 11 MB/s. This was on a 32-disk disk-group on a Raid5 vdisk. Random Read is the test that closest approximates file-server or database loads, so it is important.The "Same LUN" test showed that Write speeds are about half that of the single threaded test, which gives about equal total throughput to disk. The Read speeds are roughly comperable, giving a small net increase in total throughput from disk. Again, not sure why. The Random Read tests continue to perform very poorly, though total throughput in parallel is better than the single threaded test.
- The I/O controllers in the 4400 are able to efficiently handle more data than a single host can throw at it.
- The FATA drives introduce enough I/O bottlenecks that multiple disk-groups yield greater gains than a single big disk-group.
- Restripe operations do not cause anywhere near the problems they did on the MSA1500.
- The 4400 should not block-on-write the way the MSA did, so the NetWare cluster can have clustered volumes on it.
The "Different LUN, same disk-group," test showed similar results to the "Same LUN" test in that Write speeds were about half of single threaded yielding a total Write throughput that closely matches single-threaded. Read speeds saw a difference, with significant increases in Read throughput (about 25%). The Random Read test also saw significant increases in throughput, about 37%, but still is uncomfortably small at a net throughput of 11 MB/s.
The "Different LUN, different disk-group," test did show some I/O contention. For Write speeds, the two writers showed speeds that were 67% and 75% of the single-threaded speeds, yet showed a total throughput to disk of 174 MB/s. Compare that with the fasted single-threaded Write speed of 130 MB/s. Read performance was similar, with the two readers showing speeds that were 90% and 115% of the single-threaded performance. This gave an aggregate throughput of 133 MB/s, which is significantly faster than the 113 MB/s turned in by the fastest Reader test.
Adding disks to a disk-group appears to not significantly impact Write speeds, but significantly impact Read speeds. The Read speed dropped from 28 MB/s to 15 MB/s. Again, a backup-to-disk operation wouldn't notice this sort of activity. The Random Read test showed a similar reduction in performance. As Write speeds were not affected by restripe, the sort of cluster hard-locks we saw with the MSA1500 on the NetWare cluster will not occur with the EVA4400.
And finally, a word about controller CPU usage. In all of my testing I've yet to saturate a controller, even during restripe operations. It was the restripe ops that killed the MSA, and the EVA doesn't seem to block nearly as hard. Yes, read performance is dinged, but not nearly to the levels that the MSA does. This is because the EVA keeps its cache enabled during restripe-ops, unlike the MSA.
HP has done an excellent job tuning the caches for the EVA4400, which makes Write performance exceed Read performance in most cases. Unfortunately, you can't do the same reordering optimization tricks for Read access that you can for Writes, so Random Read is something of a worst-case scenario for these sorts of disks. HP's own documentation says that FATA drives should not be used for 'online' access such as file-servers or transactional databases. And it turns out they really meant that!
That said, these drives sequential write performance is excellent, making them very good candidates for Backup-to-Disk loads so long as fragmentation is constrained. The EVA4400 is what we really wanted two years ago, instead of the MSA1500.
Still no word on whether we're upgrading the EVA3000 to a EVA6100 this weekend, or next weekend. We should know by end-of-business today.
Labels: benchmarking, hp, msa, storage, sysadmin
Tuesday, September 02, 2008
EVA4400 testing
Right before I left Friday I started a test on the EVA4400 with a 100GB file. This is the same file-size I configured DataProtector to use for the backup-to-disk files, so it's a good test size.
Sequential Write speed: 79,065 KB/s
Sequential Read speed: 52,107 KB/s
That's a VERY good number. The Write speed above is about the same speed as I got on the MSA1500 when running against a Raid0 volume, and this is a Raid5 volume on the 4400. The 10GB file-size test I did before this one I also watched the EVA performance on the monitoring server, and controller CPU during that time was 15-20% max. Also, it really used both controllers (thanks to MPIO).
Random Write speed: 46,427 KB/s
Random Read speed: 3,721 KB/s
Now we see why HP strongly recommends against using FATA drives for random I/O. For a file server that's 80% read I/O, it would be a very poor choice. This particular random-read test is worst-case, since a 100GB file can't be cached in RAM so this represents pure array performance. File-level caching on the server itself would greatly improve performance. The same test with a 512MB file turns in a random read number of 1,633,538 KB/s which represents serving the whole test in cache-RAM on the testing station itself.
This does suggest a few other tests:
Sequential Write speed: 79,065 KB/s
Sequential Read speed: 52,107 KB/s
That's a VERY good number. The Write speed above is about the same speed as I got on the MSA1500 when running against a Raid0 volume, and this is a Raid5 volume on the 4400. The 10GB file-size test I did before this one I also watched the EVA performance on the monitoring server, and controller CPU during that time was 15-20% max. Also, it really used both controllers (thanks to MPIO).
Random Write speed: 46,427 KB/s
Random Read speed: 3,721 KB/s
Now we see why HP strongly recommends against using FATA drives for random I/O. For a file server that's 80% read I/O, it would be a very poor choice. This particular random-read test is worst-case, since a 100GB file can't be cached in RAM so this represents pure array performance. File-level caching on the server itself would greatly improve performance. The same test with a 512MB file turns in a random read number of 1,633,538 KB/s which represents serving the whole test in cache-RAM on the testing station itself.
This does suggest a few other tests:
- As above, but two 100MB files at the same time on the same LUN
- As above, but two 100MB files at the same time on different LUNs in the same Disk Group
- As above, but two 100MB files at the same time on different LUNs in different Disk Groups
Labels: benchmarking, hp, msa, storage
Monday, May 12, 2008
DataProtector 6 has a problem, continued
I posted last week about DataProtector and its Enhanced Incremental Backup. Remember that "enhincrdb" directory I spoke of? Take a look at this:
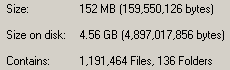
See? This is an in-progress count of one of these directories. 1.1 million files, 152MB of space consumed. That comes to an average file-size of 133 bytes. This is significantly under the 4kb block-size for this particular NTFS volume. On another server with a longer serving enhincrdb hive, the average file-size is 831 bytes. So it probably increases as the server gets older.
On the up side, these millions of weensy files won't actually consume more space for quite some time as they expand into the blocks the files are already assigned to. This means that fragmentation on this volume isn't going to be a problem for a while.
On the down side, it's going to park (in this case) 152MB of data on 4.56GB of disk space. It'll get better over time, but in the next 12 months or so it's still going to be horrendous.
This tells me two things:
Since it is highly likely that I'll be using DataProtector for OES2 systems, this is something I need to keep in mind.
See? This is an in-progress count of one of these directories. 1.1 million files, 152MB of space consumed. That comes to an average file-size of 133 bytes. This is significantly under the 4kb block-size for this particular NTFS volume. On another server with a longer serving enhincrdb hive, the average file-size is 831 bytes. So it probably increases as the server gets older.
On the up side, these millions of weensy files won't actually consume more space for quite some time as they expand into the blocks the files are already assigned to. This means that fragmentation on this volume isn't going to be a problem for a while.
On the down side, it's going to park (in this case) 152MB of data on 4.56GB of disk space. It'll get better over time, but in the next 12 months or so it's still going to be horrendous.
This tells me two things:
- When deciding where to host the enhincrdb hive on a Windows server, format that particular volume with a 1k block size.
- If HP supported NetWare as an Enhanced Incremental Backup client, the 4kb block size of NSS would cause this hive to grow beyond all reasonable proportions.
Since it is highly likely that I'll be using DataProtector for OES2 systems, this is something I need to keep in mind.
Wednesday, May 07, 2008
DataProtecter 6 has a problem
We're moving our BackupExec environment to HP DataProtector. Don't ask why, it made sense at the time.
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers in most need of de-dup technology.
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
- The first level is the mount point. Example: enhincrdb\F\
- The 2nd level are directories named 00-FF which contain the file state data itself
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers in most need of de-dup technology.
Thursday, March 06, 2008
More HP annoyances
They've recently revised their alert emails to be even more badly formatted. The below slug of text contains a critical alert. Somewhere.
This is a plain-text email, no HTML->Plain formatting weirdness. It COMES this glommed together. Time to send a cranky-gram.
Your alerts
Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DSeQ.1Lki.DKEbf000 Priority:
Critical; Products: All-in-One Storage Systems,Disk-to-disk Backup,HP Integrity
Entry-level Servers,HP Integrity High-end Servers,HP Integrity Mid-range Servers;
OS: not applicable; Release Date: Feb 26 2008; Description: Advisory: (Revision)
FIRMWARE UPGRADE or WORKAROUND REQUIRED to Prevent Rare Scenario of Potential
Logical Drive Failure on HP Smart Array Controller Attached to Multiple Drive
Arrays if Drive Failure or Incorrect Drive Replacement Occurs After Power Loss
(c01232270) Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgW.1Lki.ccEcI000 Priority:
Recommended; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP
ProLiant ML Servers,MSA Disk Arrays,Server Controllers; OS: not applicable; Release
Date: Feb 28 2008; Description: Advisory: FIRMWARE UPGRADE RECOMMENDED for Certain
HP Smart Array Controllers to Avoid False SAS and SATA Hard Drive (c01382041)
Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTf8.1Lki.DeBcEbI0 Priority:
Routine; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP ProLiant
ML Servers,HP ProLiant Packaged Cluster Servers,Server/Storage Infrastructure
Management Software; OS: not applicable; Release Date: Feb 20 2008; Description:
Advisory: HP Systems Insight Manager (HP SIM) Running in an Environment with a
Large Number of WBEM Managed Nodes May Experience Task Page Interface Slowdown or
Out of Memory Errors (c01371984) Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgo.1Lki.DAMEdA00 Priority:
Routine; Products: HP ProLiant BL Server Blades,Server Management Software; OS: not
applicable; Release Date: Feb 28 2008; Description: Advisory: Virtual Connect
Enterprise Manager (VCEM) 1.0 May Not Be Able To Add Virtual Connect (VC) Domains
to a Virtual Connect Domain Group After Updating the VC Domain Group on a ProLiant
Server (c01382035) Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgi.1Lki.CPQEca00 Priority:
Routine; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP ProLiant
Packaged Cluster Servers; OS: not applicable; Release Date: Feb 28 2008;
Description: Advisory: ProLiant Essentials Virtual Machine Manager (VMM) Displays
Incorrect VMM Warning Message on FireFox Browser for ActiveX Controls (c01382044)
Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgQ.1Lki.MAEcC000 Priority:
Routine; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP ProLiant
ML Servers,HP ProLiant Packaged Cluster Servers; OS: not applicable; Release Date:
Feb 28 2008; Description: Advisory: (c01382042) Document: Customer Advisory;
Link: http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgg.1Lki.CJcEcY00
Priority: Routine; Products: HP ProLiant DL Servers,HP ProLiant ML Servers,HP
ProLiant Packaged Cluster Servers,Server Network Interface Cards; OS: not
applicable; Release Date: Feb 28 2008; Description: Advisory: Novell NetWare
Teaming Driver (QASM.LAN) May Fail to Load After Upgrading to ProLiant Support Pack
for Novell NetWare 7.80 (or later) (c01382039) Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgU.1Lki.XIEcG000 Priority:
Routine; Products: All-in-One Storage Systems,HP Integrity Entry-level Servers,HP
Integrity High-end Servers,HP Integrity Mid-range Servers,HP ProLiant BL Server
Blades; OS: not applicable; Release Date: Feb 28 2008; Description: Advisory:
(Revision) HP ProLiant Smart Array SAS/SATA Event Notification Service Version
6.4.0.xx Does Not Log All Events to the Windows Registry (c01177411) Document:
Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTgk.1Lki.CVEEcc00 Priority:
Routine; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP ProLiant
ML Servers,HP ProLiant Packaged Cluster Servers,ProLiant Essentials Software; OS:
not applicable; Release Date: Feb 28 2008; Description: Advisory: SmartStart
Scripting Toolkit Reboot Utility May Not Respond Or May Display a Segmentation
Fault Error On a ProLiant Server Running SUSE LINUX Enterprise Server 10 Service
Pack 1 (SP1) (c01382031) Document: Customer Notice; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DTh2.1Lki.DdWYEbE0 Priority:
Routine; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP ProLiant
ML Servers; OS: not applicable; Release Date: Feb 28 2008; Description: Notice:
Linux System Health Application and Insight Management Agents (hpasm),
Lights-Out-Driver and Agents (hprsm), and NIC Agents (cmanic) Are Now Delivered as
a Single rpm Package for all Supported HP ProLiant Linux Servers (c01382040)
Document: Customer Advisory; Link:
http://alerts.hp.com/r?2.1.3KT.2ZR.xl4lg.C0m3Bi..T.DU7I.1Lki.DbNQEaL0 Priority:
Routine; Products: HP ProLiant BL Server Blades,HP ProLiant DL Servers,HP ProLiant
ML Servers,HP ProLiant Packaged Cluster Servers; OS: not applicable; Release Date:
Feb 28 2008; Description: Advisory: Virtual Machine Manager (VMM) 3.1 May Cause a
(c01383032)
This is a plain-text email, no HTML->Plain formatting weirdness. It COMES this glommed together. Time to send a cranky-gram.
Monday, January 07, 2008
I/O starvation on NetWare, another update
I've spoken before about my latency problems on the MSA1500cs. Since my last update I've spoken with Novell at length. Their own back-line HP people were thinking firmware issues to, and recommended I open another case with HP support. And if HP again tries to lay the blame on NetWare, to point their techs at the NetWare backline tech. Who will then have a talk about why exactly it is that NetWare isn't the problem in this case.
This time when I opened the case I mentioned that we see performance problems on the backup-to-disk server, which is Windows. Which is true, when the problem occurs B2D speeds drop through the floor; last Friday a 525GB backup that normally completes in 6 hours took about 50 hours. Since I'm seeing problems on more than one operating system, clearly this is a problem with the storage device.
The first line tech agreed, and escalated. The 2nd line tech said (paraphrased):
That may be where we have to go with this. Unfortunately, I don't think we have 16TB of disk-drives available to fully mirror the cluster. That'll be a significant expense. So, I think we have some rethinking to do regarding what we use this device for.
This time when I opened the case I mentioned that we see performance problems on the backup-to-disk server, which is Windows. Which is true, when the problem occurs B2D speeds drop through the floor; last Friday a 525GB backup that normally completes in 6 hours took about 50 hours. Since I'm seeing problems on more than one operating system, clearly this is a problem with the storage device.
The first line tech agreed, and escalated. The 2nd line tech said (paraphrased):
I'm seeing a lot of parity RAID LUNs out there. This sort of RAID uses CPU on the MSA1000 controllers, so the results you're seeing are normal for this storage system.Which, if true, puts the onus of putting up with a badly behaved I/O system onto NetWare again. The tech went on to recommend RAID1 for the LUNs that need high performance when doing array operations that disable the internal cache. Which, as far as I can figure, would work. We're not bottlenecking on I/O to the physical disks, the bottleneck is CPU on the MSA1000 controller that's active. Going RAID1 on the LUNs would keep speeds very fast even when doing array operations.
That may be where we have to go with this. Unfortunately, I don't think we have 16TB of disk-drives available to fully mirror the cluster. That'll be a significant expense. So, I think we have some rethinking to do regarding what we use this device for.
Wednesday, November 28, 2007
I/O starvation on NetWare, HP update
Last week I talked about a problem we're having with the HP MSA1500cs and our NetWare cluster. The problem is still there, of course. I've opened cases with both HP and Novell to handle this one. HP because I really thing that such command latencies are a defect, and Novell since they're having starvation issues with clusters.
This morning I got a voice-mail from HP, an update for our case. Greatly summarized:
Especially since I don't think I've made back-line on the Novell case yet. They're involved, but I haven't been referred to a new support engineer yet.
This morning I got a voice-mail from HP, an update for our case. Greatly summarized:
The MSA team has determined that your device is working perfectly, and can find no defects. They've referred the case to the NetWare software team.Or...
Working as designed. Fix your software. Talk to Novell.Which I'm doing. Now to see if I can light a fire on the back-channels, or if we've just made HP admit that these sorts of command latencies are part of the design and need to be engineered around in software. Highly frustrating.
Especially since I don't think I've made back-line on the Novell case yet. They're involved, but I haven't been referred to a new support engineer yet.
Labels: clustering, hp, msa, netware, novell, OES, storage, sysadmin
Monday, November 26, 2007
Adding attachments to an open HP Support case
I don't think this is documented anywhere. But I just learned how to add updates to the HP case-file. Including attachments.
To: support_am@hp.comAny attachments to it will be automatically imported into the case. LOOKING at the case itself is a lot more complicated, and I'm still not sure of the steps. But this should be of use to some of you.
Subject:
CASE_ID_NUM: [case number, such as 36005555555]
MESSAGE: [text]
Wednesday, November 21, 2007
I/O starvation on NetWare
The MSA1500cs we've had for a while has shown a bad habit. It is visible when you connect a serial cable to the management port on the MSA1000 controller, and doing a "show perf" after starting performance tracking. The line in question is "Avg Command Latency:", which is a measure of how long it takes to execute an I/O operation. Under normal circumstances this metric stays between 5-30ms. When things go bad, I've seen it as far as 270ms.
This is a problem with our cluster nodes. Our cluster nodes can seen LUNs on both the MSA1500cs and the EVA3000. The EVA is where the cluster has been housed since it started, and the MSA has taken up two low-I/O-volume volumes to make space on the EVA.
IF the MSA is in the high Avg Command Latency state, and
IF a cluster node is doing a large Write to the MSA (such as a DVD ISO image, or B2D operation),
THEN "Concurrent Disk Requests" in Monitor go north of 1000
This is a dangerous state. If this particular cluster node is housing some higher trafficked volumes, such as FacShare:, the laggy I/O is competing with regular (fast) I/O to the EVA. If this sort of mostly-Read I/O is concurrent with the above heavy Write situation it can cause the cluster node to not write to the Cluster Partition on time and trigger a poison-pill from the Split Brain Detector. In short, the storage heart-beat to the EVA (where the Cluster Partition lives) gets starved out in the face of all the writes to the laggy MSA.
Users definitely noticed when the cluster node was in such a heavy usage state. Writes and Reads took a loooong time on the LUNs hosted on the fast EVA. Our help-desk recorded several "unable to map drive" calls when the nodes were in that state, simply because a drive-mapping involves I/O and the server was too busy to do it in the scant seconds it normally does.
This is sub-optimal. This also doesn't seem to happen on Windows, but I'm not sure of that.
This is something that a very new feature in the Linux kernel could help out, that that's to introduce the concept of 'priority I/O' to the storage stack. I/O with a high priority, such as cluster heart-beats, gets serviced faster than I/O of regular priority. That could prevent SBD abends. Unfortunately, as the NetWare kernel is no longer under development and just under Maintenance, this is not likely to be ported to NetWare.
I/O starvation. This shouldn't happen, but neither should 270ms I/O command latencies.
This is a problem with our cluster nodes. Our cluster nodes can seen LUNs on both the MSA1500cs and the EVA3000. The EVA is where the cluster has been housed since it started, and the MSA has taken up two low-I/O-volume volumes to make space on the EVA.
IF the MSA is in the high Avg Command Latency state, and
IF a cluster node is doing a large Write to the MSA (such as a DVD ISO image, or B2D operation),
THEN "Concurrent Disk Requests" in Monitor go north of 1000
This is a dangerous state. If this particular cluster node is housing some higher trafficked volumes, such as FacShare:, the laggy I/O is competing with regular (fast) I/O to the EVA. If this sort of mostly-Read I/O is concurrent with the above heavy Write situation it can cause the cluster node to not write to the Cluster Partition on time and trigger a poison-pill from the Split Brain Detector. In short, the storage heart-beat to the EVA (where the Cluster Partition lives) gets starved out in the face of all the writes to the laggy MSA.
Users definitely noticed when the cluster node was in such a heavy usage state. Writes and Reads took a loooong time on the LUNs hosted on the fast EVA. Our help-desk recorded several "unable to map drive" calls when the nodes were in that state, simply because a drive-mapping involves I/O and the server was too busy to do it in the scant seconds it normally does.
This is sub-optimal. This also doesn't seem to happen on Windows, but I'm not sure of that.
This is something that a very new feature in the Linux kernel could help out, that that's to introduce the concept of 'priority I/O' to the storage stack. I/O with a high priority, such as cluster heart-beats, gets serviced faster than I/O of regular priority. That could prevent SBD abends. Unfortunately, as the NetWare kernel is no longer under development and just under Maintenance, this is not likely to be ported to NetWare.
I/O starvation. This shouldn't happen, but neither should 270ms I/O command latencies.
Labels: clustering, hp, msa, netware, novell, OES, storage, sysadmin
Tuesday, January 30, 2007
That's odd
HP is advertising their blade systems. I saw an ad for one this weekend on SciFi, and now a banner ad on the front page of economist.com.
This is a system that has zero presence in the home, entirely in datacenters. This is clearly an effort to influence decision makers outside of industry rags like ComputerWorld or NetworkWorld. Yeah, a lot of fellow IT workers I know were sad when Farscape died, so I guess we have a lot of SciFi buffs around.
Hmm.
This is a system that has zero presence in the home, entirely in datacenters. This is clearly an effort to influence decision makers outside of industry rags like ComputerWorld or NetworkWorld. Yeah, a lot of fellow IT workers I know were sad when Farscape died, so I guess we have a lot of SciFi buffs around.
Hmm.
Labels: hp
Wednesday, August 02, 2006
Near heart failure
The thing that caused me to go into near heart failure was one server's misbehaving. I had just finished applying SP5 to one of the WUF servers and it was rebooting. It didn't come right up so I go back and look to see where it might be hung up. Instead what I see is the "Multiple abends occuring, processor halted" screen. Aie!
And it seemed to happen every time on reboot. Some quick looking showed that it happened pretty quickly after NILE.NLM loaded. But due to the nature of the problem, not abend.log was generated for me to know what exactly faulted.
So I drop 'er down to DOS and to a "SERVER -ns -na" and step through the launch process. During this time I noticed that the HP BIOS is expecting a "Windows" server. I thought that was odd, and put it on the list of things to change. I step through boot, and sure enough, during AUTOEXEC.NCF processing it bombs on the multiple-abends-occuring problem. Arrrg. Still don't know what module load caused the problem, though.
So I reboot and change the OS the BIOS is expecting to be NetWare, and reboot. It comes up just peachy.
oooookaaaay.... Didn't know it was that twitchy. Anyway, it is up and running just fine now.
Tags: NetWare, HP
And it seemed to happen every time on reboot. Some quick looking showed that it happened pretty quickly after NILE.NLM loaded. But due to the nature of the problem, not abend.log was generated for me to know what exactly faulted.
So I drop 'er down to DOS and to a "SERVER -ns -na" and step through the launch process. During this time I noticed that the HP BIOS is expecting a "Windows" server. I thought that was odd, and put it on the list of things to change. I step through boot, and sure enough, during AUTOEXEC.NCF processing it bombs on the multiple-abends-occuring problem. Arrrg. Still don't know what module load caused the problem, though.
So I reboot and change the OS the BIOS is expecting to be NetWare, and reboot. It comes up just peachy.
oooookaaaay.... Didn't know it was that twitchy. Anyway, it is up and running just fine now.
Tags: NetWare, HP
![]()
