Thursday, February 11, 2010
Spending money
Today we spent more money in one day than I've ever seen done here. Why? Well substantiated rumor had it that the Governor had a spending freeze directive on her desk. Unlike last year's freeze, this one would be the sort passed down during the 2001-02 recession; nothing gets spent without OFM approval. Veterans of that era noted that such approval took a really long time, and only sometimes came. Office scuttle-butt was mum on whether or not consumable purchases like backup tapes would be covered.
We cut purchase orders today and rushed them through Purchasing. A Purchasing who was immensely snowed under, as can be well expected. I think final signatures get signed tomorrow.
What are we getting? Three big things:
The last thing we have is an email archiving system. We already know what we want, but we're waiting on determination of whether or not we can spend that already ear-marked money.
Unfortunately, I'll be finding out a week from Monday. I'll be out of the office all next week. Bad timing for it, but can't be avoided.
We cut purchase orders today and rushed them through Purchasing. A Purchasing who was immensely snowed under, as can be well expected. I think final signatures get signed tomorrow.
What are we getting? Three big things:
- A new LTO4 tape library. I try not to gush lovingly at the thought, but keep in mind I've been dealing with SDLT320 and old tapes. I'm trying not to let all that space go to my head. 2 drives, 40-50 slots, fibre attached.
Made of love. No gushing, no gushing... - Fast, cheap storage. Our EVA6100 is just too expensive to keep feeding. So we're getting 8TB of 15K fast storage. We needs it, precious.
- Really cheap storage. Since the storage area networking options all came in above our stated price-point, we're ending up with direct-attached. Depending on how we slice it, between 30-35TB of it. Probably software ISCSI and all the faults inherent in the setup. We still need to dicker over software.
The last thing we have is an email archiving system. We already know what we want, but we're waiting on determination of whether or not we can spend that already ear-marked money.
Unfortunately, I'll be finding out a week from Monday. I'll be out of the office all next week. Bad timing for it, but can't be avoided.
Tuesday, February 02, 2010
Budget plans
Washington State has a $2.6 Billion deficit for this year. In fact, the finance people point out that if something isn't done the WA treasury will run dry some time in September and we'll have to rely on short-term loans. As this is not good, the Legislature is attempting to come up with some way to fill the hole.
As far as WWU is concerned, we know we'll be passed some kind of cut. We don't know the size, nor do we know what other strings may be attached to the money we do get. So we're planning for various sizes of cuts.
One thing that is definitely getting bandied about is the idea of 'sweeping' unused funds at end-of-year in order to reduce the deficits. As anyone who has ever worked in a department subject to a budget knows, the idea of having your money taken away from you for being good with your money runs counter to every bureaucratic instinct. I have yet to meet the IT department that considers themselves fully funded. My old job did that; our Fiscal year ended 12/15, which meant that we bought a lot of stuff in October and November with the funds we'd otherwise have to give back (a.k.a. "Christmas in October"). Since WWU's fiscal year starts 7/1, this means that April and May will become 'use it or lose it' time.
Sweeping funds is a great way to reduce fiscal efficiency.
In the end, what this means is that the money tree is actually producing at the moment. We have a couple of crying needs that may actually get addressed this year. It's enough to completely fix our backup environment, OR do some other things. We still have to dicker over what exactly we'll fix. The backup environment needs to be made better at least somewhat, that much I know. We have a raft of servers that fall off of cheap maintenance in May (i.e. they turn 5). We have a need for storage that costs under $5/GB but is still fast enough for 'online' storage (i.e. not SATA). As always, the needs are many, and the resources few.
At least we HAVE resources at the moment. It's a bad sign when you have to commiserate with your end-users over not being able to do cool stuff, or tell researchers they can't do that particular research since we have no where to store their data. Baaaaaad. We haven't quite gotten there yet, but we can see it from where we are.
As far as WWU is concerned, we know we'll be passed some kind of cut. We don't know the size, nor do we know what other strings may be attached to the money we do get. So we're planning for various sizes of cuts.
One thing that is definitely getting bandied about is the idea of 'sweeping' unused funds at end-of-year in order to reduce the deficits. As anyone who has ever worked in a department subject to a budget knows, the idea of having your money taken away from you for being good with your money runs counter to every bureaucratic instinct. I have yet to meet the IT department that considers themselves fully funded. My old job did that; our Fiscal year ended 12/15, which meant that we bought a lot of stuff in October and November with the funds we'd otherwise have to give back (a.k.a. "Christmas in October"). Since WWU's fiscal year starts 7/1, this means that April and May will become 'use it or lose it' time.
Sweeping funds is a great way to reduce fiscal efficiency.
In the end, what this means is that the money tree is actually producing at the moment. We have a couple of crying needs that may actually get addressed this year. It's enough to completely fix our backup environment, OR do some other things. We still have to dicker over what exactly we'll fix. The backup environment needs to be made better at least somewhat, that much I know. We have a raft of servers that fall off of cheap maintenance in May (i.e. they turn 5). We have a need for storage that costs under $5/GB but is still fast enough for 'online' storage (i.e. not SATA). As always, the needs are many, and the resources few.
At least we HAVE resources at the moment. It's a bad sign when you have to commiserate with your end-users over not being able to do cool stuff, or tell researchers they can't do that particular research since we have no where to store their data. Baaaaaad. We haven't quite gotten there yet, but we can see it from where we are.
Tuesday, January 12, 2010
The costs of backup upgrades
Our tape library is showing its years, and it's time to start moving the mountain required to get it replaced with something. So this afternoon I spent some quality time with google, a spread-sheet, and some oldish quotes from HP. The question I was trying to answer is what's the optimal mix of backup to tape and backup to disk using HP Data Protector. The results were astounding.
Data Protector licenses backup-to-disk capacity by the amount of space consumed in the B2D directories. You have 15TB parked in your backup-to-disk archives, you pay for 15TB of space.
Data Protector has a few licenses for tape libraries. They have costs for each tape drive over 2, another license for libraries with between 61-250 slots, and another license for unlimited slots. There is no license for fibre-attached libraries like BackupExec and others do.
Data Protector does not license per backed up host, which is theoretically a cost savings.
When all is said and done, DP costs about $1.50 per GB in your backup to disk directories. In our case the price is a bit different since we've sunk some of those costs already, but they're pretty close to a buck fiddy per GB for Data Protector licensing alone. I haven't even gotten to physical storage costs yet, this is just licensing.
Going with an HP tape library (easy for me to spec, which is why I put it into the estimates), we can get an LTO4-based tape library that should meet our storage growth needs for the next 5 years. After adding in the needed DP licenses, the total cost per GB (uncompressed, mind) is on the order of $0.10 per GB. Holy buckets!
Calming down some, taking our current backup volume and apportioning the price of largest tape library I estimated over that backup volume and the price rises to $1.01/GB. Which means that as we grow our storage, the price-per-GB drops as less of the infrastructure is being apportioned to each GB. That's a rather shocking difference in price.
Clearly, HP really really wants you to use their de-duplication features for backup-to-disk. Unfortunately for HP, their de-duplication technology has some serious deficiencies when presented with our environment so we can't use it for our largest backup targets.
But to answer the question I started out with, what kind of mix should we have, the answer is pretty clear. As little backup-to-disk space as we can get away with. The stuff has some real benefits, as it allows us to stage backups to disk and then copy to tape during the day. But for long term storage, tape is by far the more cost-effective storage medium. By far.
Data Protector licenses backup-to-disk capacity by the amount of space consumed in the B2D directories. You have 15TB parked in your backup-to-disk archives, you pay for 15TB of space.
Data Protector has a few licenses for tape libraries. They have costs for each tape drive over 2, another license for libraries with between 61-250 slots, and another license for unlimited slots. There is no license for fibre-attached libraries like BackupExec and others do.
Data Protector does not license per backed up host, which is theoretically a cost savings.
When all is said and done, DP costs about $1.50 per GB in your backup to disk directories. In our case the price is a bit different since we've sunk some of those costs already, but they're pretty close to a buck fiddy per GB for Data Protector licensing alone. I haven't even gotten to physical storage costs yet, this is just licensing.
Going with an HP tape library (easy for me to spec, which is why I put it into the estimates), we can get an LTO4-based tape library that should meet our storage growth needs for the next 5 years. After adding in the needed DP licenses, the total cost per GB (uncompressed, mind) is on the order of $0.10 per GB. Holy buckets!
Calming down some, taking our current backup volume and apportioning the price of largest tape library I estimated over that backup volume and the price rises to $1.01/GB. Which means that as we grow our storage, the price-per-GB drops as less of the infrastructure is being apportioned to each GB. That's a rather shocking difference in price.
Clearly, HP really really wants you to use their de-duplication features for backup-to-disk. Unfortunately for HP, their de-duplication technology has some serious deficiencies when presented with our environment so we can't use it for our largest backup targets.
But to answer the question I started out with, what kind of mix should we have, the answer is pretty clear. As little backup-to-disk space as we can get away with. The stuff has some real benefits, as it allows us to stage backups to disk and then copy to tape during the day. But for long term storage, tape is by far the more cost-effective storage medium. By far.
Monday, December 28, 2009
Bad tapes
It seems that HP Data Protector and BackupExec 10 have different opinions on what constitutes a bad tape. BackupExec seems to survive them better. This means that as we cycle old media into the new Data Protector environment we're getting the occasional bad tape. We've been averaging 3 bad tapes per 40 tape rotation.
While that not may sound like a lot, it really is. Our very large backups are extremely vulnerable to bad tapes, since all it takes is one bad tape to kill an entire backup session. When you're doing a backup of 1.3TB of data, you don't want those backups to fail.
Take that 1.3TB backup. We're backing up to SDL320 media, so we're averaging somewhere between 180GB and 220GB a tape depending on what kinds of files are being backed up. So that's 7-8 tapes for this one backup. How likely is it that this 7 to 8 tape backup will include at least one of the 3 bad tapes?
When the first tape is picked the chance is 3 in 40 (7.5%).
When the second tape is picked, assuming the first tape was good, the chance is 3 in 39 (7.69%).
When the third tape is picked, presuming the first two were good, the chance is 3 in 38 (7.89%).
When the 7th tape is picked, presuming the first six were good, the chance has increased to 3 in 34 (8.82%)
8.82% doesn't sound like much. However, the probability is cumulative. The true probability can be computed:
(3/40)+(3/39)+(3/38)+(3/37)+(3/36)+(3/35)+(3/34) = 0.56923444 or 56.92%
So with 3 bad tapes in a given 40 tape set, the chance of this one 7 tape backup having at least one of them in the tape set is over 50%. For an 8 tape backup the probability increases to 66.01%.
The true probability is a different number, since these backups are taken concurrent with other backups. So when the 7th tape gets picked, the number of available tapes is much less than 34, and the number of bad tapes still waiting to be found may not be 3. Also, these backups are mutliplexed so the true tape set may be as high as 9 tapes for this backups if that one backup target is slow in sending data to the backup server.
So the true probability is not 56.92%, it changes on a week to week basis. However, 56.92% (or 66%) is a good baseline. Some weeks it'll be a lot more. Others, such as weeks where the bad tapes are found by other processes and the target server is streaming fast, less.
We have a couple more weeks until we've cycled through all of our short-retention media. At that point our error rate should drop a lot. Until then, it's like dodging artillery shells.
While that not may sound like a lot, it really is. Our very large backups are extremely vulnerable to bad tapes, since all it takes is one bad tape to kill an entire backup session. When you're doing a backup of 1.3TB of data, you don't want those backups to fail.
Take that 1.3TB backup. We're backing up to SDL320 media, so we're averaging somewhere between 180GB and 220GB a tape depending on what kinds of files are being backed up. So that's 7-8 tapes for this one backup. How likely is it that this 7 to 8 tape backup will include at least one of the 3 bad tapes?
When the first tape is picked the chance is 3 in 40 (7.5%).
When the second tape is picked, assuming the first tape was good, the chance is 3 in 39 (7.69%).
When the third tape is picked, presuming the first two were good, the chance is 3 in 38 (7.89%).
When the 7th tape is picked, presuming the first six were good, the chance has increased to 3 in 34 (8.82%)
8.82% doesn't sound like much. However, the probability is cumulative. The true probability can be computed:
(3/40)+(3/39)+(3/38)+(3/37)+(3/36)+(3/35)+(3/34) = 0.56923444 or 56.92%
So with 3 bad tapes in a given 40 tape set, the chance of this one 7 tape backup having at least one of them in the tape set is over 50%. For an 8 tape backup the probability increases to 66.01%.
The true probability is a different number, since these backups are taken concurrent with other backups. So when the 7th tape gets picked, the number of available tapes is much less than 34, and the number of bad tapes still waiting to be found may not be 3. Also, these backups are mutliplexed so the true tape set may be as high as 9 tapes for this backups if that one backup target is slow in sending data to the backup server.
So the true probability is not 56.92%, it changes on a week to week basis. However, 56.92% (or 66%) is a good baseline. Some weeks it'll be a lot more. Others, such as weeks where the bad tapes are found by other processes and the target server is streaming fast, less.
We have a couple more weeks until we've cycled through all of our short-retention media. At that point our error rate should drop a lot. Until then, it's like dodging artillery shells.
Labels: backup
Wednesday, December 23, 2009
That TCP Windowing fault
Here is the smoking gun, let me show you it (new window).
That's an entire TCP segment. Packet 339 there is the end of the TCP window as far as the NetWare side is concerned. Packet 340 is a delayed ACK, which is a normal TCP timeout. Then follows a somewhat confusing series of packets and the big delay in packet 345.
That pattern, the 200ms delay, and 5 packets later a delay measurable in full seconds, is common throughout the capture. They seem to happen on boundaries between TCP windows. Not all windows, but some windows. Looking through the captures, it seems to happen when the window has an odd number of packets in it. The Windows server is ACKing after every two packets, which is expected. It's when it has to throw a Delayed ACK into the mix, such as the odd packet at the end of a 27 packet window, is when we get our unstable state.
The same thing happened on a different server (NW65SP8) before I turned off "Receive Window Auto Tuning" on the Server 2008 server. After I turned that off, the SP8 server stopped doing that and started streaming at expectedly high data-rates. The rates still aren't as good as they were when doing the same backup to the Server 2003 server, but at least it's a lot closer. 28 hours for this one backup versus 21, instead of over 5 days before I made the change.
The packets you see are for an NW65 SP5 server after the update to the Windows server. Clearly there are some TCP/IP updates in the later NetWare service-packs that help it talk to Server 2008's TCP/IP stack.
That's an entire TCP segment. Packet 339 there is the end of the TCP window as far as the NetWare side is concerned. Packet 340 is a delayed ACK, which is a normal TCP timeout. Then follows a somewhat confusing series of packets and the big delay in packet 345.
That pattern, the 200ms delay, and 5 packets later a delay measurable in full seconds, is common throughout the capture. They seem to happen on boundaries between TCP windows. Not all windows, but some windows. Looking through the captures, it seems to happen when the window has an odd number of packets in it. The Windows server is ACKing after every two packets, which is expected. It's when it has to throw a Delayed ACK into the mix, such as the odd packet at the end of a 27 packet window, is when we get our unstable state.
The same thing happened on a different server (NW65SP8) before I turned off "Receive Window Auto Tuning" on the Server 2008 server. After I turned that off, the SP8 server stopped doing that and started streaming at expectedly high data-rates. The rates still aren't as good as they were when doing the same backup to the Server 2003 server, but at least it's a lot closer. 28 hours for this one backup versus 21, instead of over 5 days before I made the change.
The packets you see are for an NW65 SP5 server after the update to the Windows server. Clearly there are some TCP/IP updates in the later NetWare service-packs that help it talk to Server 2008's TCP/IP stack.
Saturday, December 19, 2009
Sniffing packets
When I first started this sysadmin gig 'round about 1997, Windows based packet sniffers were still in their infancy. In fact, the word 'sniffer' was (and probably still is) a trademarked term for the software and hardware package for, er, sniffing packets. Sniffer. So when I needed to figure out a problem on the network, I went to the Network Guys who plugged their Sniffer into any available port on the 10baseT hub I needed analysis on and went to work. They told me what was wrong. Like a JetDirect card transmitting packets whenever it sensed a packet on the wire, thus bringing the network to is knees. Things like that.
Time passed and Sniffer was bought by Network Associates. Who then added a zero to the price because that package really did have a lock on the market. The next rev then more than doubled the already inflated price. So when it came time to renew/upgrade, our Sniffer couldn't handle Fast Ethernet, the price was eye watering. So. On came the free sniffers.
At first I was using Ether Boy, a now long lost packet sniffer. But eventually I found Ethereal (now WireShark), and I went to work. By the time I left my old job in 2003 I already had a rep for knowing WTF I was looking at, and the network guys didn't bat an eyelash when I asked for a span port. This ability was very handy when diagnosing slow Novell logins.
Fast forward to now. Right now I'm trying to figure out why the heck a certain NetWare server is so slow talking to the Data Protector media agent. It isn't obviously a TSA problem, but I've had problems with DP and NW talking to each other on the TCP level so that's where I'm looking now. Unfortunately for me, the desktop-grade GigE nic I have on the span isn't, shall we say, resourced enough to sniff a full GigE stream without at least a few buffer overruns. So I'm not getting ALL of the packets.
When I asked for the span port, the telecom guy said he greatly respected my ability to dig in to TCP issues. And said it in the voice of, "I think you're better at that kind of troubleshooting than we are." Which is a bit disconcerting to hear from your telecom router-gods. But there it is. What it means is that I can't very well ask for help interpreting these traces.
So far I've been able to determine that there is something hinky going on with network delays. There are some 200ms delays in there, which hints strongly at a failed protocol negotiation somewhere. But there are some rather longer delays, and it could be due to window size negotiation problems. Server 2008, the media-agent server, has a much newer TCP/IP stack than NetWare so it is entirely possible that they just don't work well together. I don't understand that quite well enough to manually deconstruct what's going on, so that's what I'm googling on right now.
And why Saturday? Because of course the volume that's doing this is our single largest and it is on the weekend where it is in the failed state where I can pry the hood off and look. Who knows, I may resort to posting packets and crowd sourcing the problem.
Update 12/23/09: Found it.
Time passed and Sniffer was bought by Network Associates. Who then added a zero to the price because that package really did have a lock on the market. The next rev then more than doubled the already inflated price. So when it came time to renew/upgrade, our Sniffer couldn't handle Fast Ethernet, the price was eye watering. So. On came the free sniffers.
At first I was using Ether Boy, a now long lost packet sniffer. But eventually I found Ethereal (now WireShark), and I went to work. By the time I left my old job in 2003 I already had a rep for knowing WTF I was looking at, and the network guys didn't bat an eyelash when I asked for a span port. This ability was very handy when diagnosing slow Novell logins.
Fast forward to now. Right now I'm trying to figure out why the heck a certain NetWare server is so slow talking to the Data Protector media agent. It isn't obviously a TSA problem, but I've had problems with DP and NW talking to each other on the TCP level so that's where I'm looking now. Unfortunately for me, the desktop-grade GigE nic I have on the span isn't, shall we say, resourced enough to sniff a full GigE stream without at least a few buffer overruns. So I'm not getting ALL of the packets.
When I asked for the span port, the telecom guy said he greatly respected my ability to dig in to TCP issues. And said it in the voice of, "I think you're better at that kind of troubleshooting than we are." Which is a bit disconcerting to hear from your telecom router-gods. But there it is. What it means is that I can't very well ask for help interpreting these traces.
So far I've been able to determine that there is something hinky going on with network delays. There are some 200ms delays in there, which hints strongly at a failed protocol negotiation somewhere. But there are some rather longer delays, and it could be due to window size negotiation problems. Server 2008, the media-agent server, has a much newer TCP/IP stack than NetWare so it is entirely possible that they just don't work well together. I don't understand that quite well enough to manually deconstruct what's going on, so that's what I'm googling on right now.
And why Saturday? Because of course the volume that's doing this is our single largest and it is on the weekend where it is in the failed state where I can pry the hood off and look. Who knows, I may resort to posting packets and crowd sourcing the problem.
Update 12/23/09: Found it.
Tuesday, December 15, 2009
Learning new backup software
It has been no secret that we've been trying to migrate away from BackupExec (10d) to HP's Data Protector. Originally this was due to cost reasons, but we were either sold a bill of goods, or there was a fundamental misunderstanding somewhere along the way. Your choice as to which it really was. In short, the costs have been about the same or even a bit more than staying with BE. However, sunk costs are sunk, so once the switch was made DP became the cheaper course of the future.
Which brings us to the current state. We've finally pried loose funds to license the Scalar 100 we have for our tape backup solution, and we're in the process of getting that working with DP. As with all backup software, it behaves a bit differently than others.
And now, a digression.
It is my opinion that all backup software everywhere is fundamentally cantankerous, finicky, and locked in obscure traditions. The traditions I'm speaking of are sourced in the ancestral primary supported platforms, and the UI and rotation metaphors created 5, 10, 15, 20 years ago. The cantankerous and finicky parts come from a combination of supporting the cantankerous and finicky tape hardware and the process of getting data off of servers for backup.
I know there are people who love their backup solutions with an unholy passion. I do not understand this. Perhaps I just haven't worked with the right environment.
Back to my point.
Data Protector continues the tradition of cantankerous, finicky software locked into an obscure tradition. I am not surprised by this, but it is still disheartening. How it interacts with our tape robot is sub-optimal in many ways, which will ultimately require hand editing a text file to configure timeout paramters in an optimal way. This reflects DP's origin as a UNIX based backup ported to Windows. It only got a usable GUI very recently, and until DP 6.10 came out required rsh and rcp for their Unix deployment server. I kid you not. DP6.11 at least supports ssh and scp.
It's also not working well with our NetWare backups. I've blogged about this one before, but didn't end up posting the solution to the last round of problems. It turned out to be an out of date driver on the part of the DP backup-to-disk server, as it wasn't ACKing packets fast enough. Updated the driver, the backup started flying. Now that we've got the Scalar in the mix, and backing up to a new server, some new problems have emerged. So far they look to be in the NetWare TSA stack rather than on the DP side (at least, that's what the symptoms look like. I still need to look at packets to be sure), which is unfortunate since 1: Novell isn't going to fix the TSAs on NetWare, and 2: We're getting rid of NetWare in the near future. But not near enough that we can just forget the backups until we migrate. Suck-up-and-deal appears to be our solution. (DP does have OES2 agents, by the way)
Our Windows backups all are looking decent, though. That's something anyway. At least, when the Scalar isn't throwing monkey wrenches into DP's little world.
Which brings us to the current state. We've finally pried loose funds to license the Scalar 100 we have for our tape backup solution, and we're in the process of getting that working with DP. As with all backup software, it behaves a bit differently than others.
And now, a digression.
It is my opinion that all backup software everywhere is fundamentally cantankerous, finicky, and locked in obscure traditions. The traditions I'm speaking of are sourced in the ancestral primary supported platforms, and the UI and rotation metaphors created 5, 10, 15, 20 years ago. The cantankerous and finicky parts come from a combination of supporting the cantankerous and finicky tape hardware and the process of getting data off of servers for backup.
I know there are people who love their backup solutions with an unholy passion. I do not understand this. Perhaps I just haven't worked with the right environment.
Back to my point.
Data Protector continues the tradition of cantankerous, finicky software locked into an obscure tradition. I am not surprised by this, but it is still disheartening. How it interacts with our tape robot is sub-optimal in many ways, which will ultimately require hand editing a text file to configure timeout paramters in an optimal way. This reflects DP's origin as a UNIX based backup ported to Windows. It only got a usable GUI very recently, and until DP 6.10 came out required rsh and rcp for their Unix deployment server. I kid you not. DP6.11 at least supports ssh and scp.
It's also not working well with our NetWare backups. I've blogged about this one before, but didn't end up posting the solution to the last round of problems. It turned out to be an out of date driver on the part of the DP backup-to-disk server, as it wasn't ACKing packets fast enough. Updated the driver, the backup started flying. Now that we've got the Scalar in the mix, and backing up to a new server, some new problems have emerged. So far they look to be in the NetWare TSA stack rather than on the DP side (at least, that's what the symptoms look like. I still need to look at packets to be sure), which is unfortunate since 1: Novell isn't going to fix the TSAs on NetWare, and 2: We're getting rid of NetWare in the near future. But not near enough that we can just forget the backups until we migrate. Suck-up-and-deal appears to be our solution. (DP does have OES2 agents, by the way)
Our Windows backups all are looking decent, though. That's something anyway. At least, when the Scalar isn't throwing monkey wrenches into DP's little world.
Labels: backup
Thursday, October 15, 2009
It's the little things
Right now our Microsoft migration schedule is hung up on backup licenses. Backing up clustered servers requires extensions, which we didn't notice back when we priced out the project. It is things like these that make for cost-overruns. The long and the short of it is, we're not migrating anything until we can legally back up the new environment. Period. That's just how it is.
As most of the budget arm-wrestling happens above me, I only get bits and pieces. Since we don't spend our money, we spend other people's money, we have to convince other people that this money needs to be spent. I understand there was some pushback when the quote came in, and we've been educating about what exactly it would mean if we don't do this.
I understand the order is in the works, and we're just waiting on license codes. But until they arrive (electronic delivery? What's dat?) we simply can not move forward. That's just how it is.
As most of the budget arm-wrestling happens above me, I only get bits and pieces. Since we don't spend our money, we spend other people's money, we have to convince other people that this money needs to be spent. I understand there was some pushback when the quote came in, and we've been educating about what exactly it would mean if we don't do this.
I understand the order is in the works, and we're just waiting on license codes. But until they arrive (electronic delivery? What's dat?) we simply can not move forward. That's just how it is.
Wednesday, July 15, 2009
Where DIY belongs
The question of: "When should you built it your self and when should you get it off the shelf?" is one that varies from workplace to workplace. We heard several different variants of that when were interviewing for the Vice Provost for IT last year. Some candidates only did home-brew when no off the shelf package was available, others looked at the total cost of both and chose from there. This is a nice proxy question for, "What is the role of open source in your environment," as it happens.
Backups are one area where duct tape and bailing wire is to be discouraged most emphatically.
And now, a moment on tar. It is a very versatile tool, and is what a lot of unixy backup packages are built around. The main problem with backup and restore is not getting data to the backup medium, it is keeping track of what data is on which medium. Also in these days of the backup-to-disk, de-duplication is also in the mix and that's something tar can't do yet. So while you can build a tar-and-bash backup system from scratch without paying a cent, it will be lacking in certain very useful features.
Also? Tar doesn't work nearly as well on Windows.
Your backup system is one area you really do not want to invest a lot of developer creativity. You need it to be bullet proof, fault tolerant, able to handle a variety of data-types, and easy to maintain. Even the commercial packages fail some of these points some of the time, and the home brew systems fall apart much more often relative to these. The big backup boys have agents that allow backups of Oracle DBs, Linux filesystems, Exchange, and Sharepoint all to the same backup system, a home-brew application would have to get very creative to do the same thing; the problem gets even worse when it comes to restore.
Disaster Recovery is another area in which duct tape and bailing wire are to be discouraged most emphatically.
There are battle-tested open-source packages out there that will help with this (DRBD for one), depending on your environment. They're even widely used so finding someone to replace the sysadmin who just had a run in with a city bus is not that hard. Rsync can do a lot as well, so long as the scale is small. Most single systems can have something cobbled together.
Problems arise when you start talking Windows, very complex installations, or money is a major issue. If you throw enough money at a problem, most disaster recovery problems become a lot less complex. There is a lot of industry investment in DR infrastructure, so the tools are out there. Doing it on a shoe-string means that your disaster recovery also hangs by a shoe-string. If you're doing DR just to satisfy your auditors and don't plan on ever actually using it, that's one thing. But if you really expect to recover from a major disaster on that shoe-string you'll be sorely surprised when that string snaps.
Business Continuity is an area where duct tape and bailing wire should be flatly refused.
BC is in many ways DR with a much shorter recovery time. If you had problems getting your DR funded correctly, BC shouldn't even be on the timeline. Again, if it is just so you can check a box on some audit report, that's one thing. Expecting to run on such a rig is quite another.
And finally, if you do end up cobbling together backup, disaster recovery, or business continuity systems from their component parts, testing the system is even more important. In many cases testing DR/BC takes a production outage of some kind, which makes it hard to schedule tests. But testing is the only way to find out if your shoe-string can stand the load.
Backups are one area where duct tape and bailing wire is to be discouraged most emphatically.
And now, a moment on tar. It is a very versatile tool, and is what a lot of unixy backup packages are built around. The main problem with backup and restore is not getting data to the backup medium, it is keeping track of what data is on which medium. Also in these days of the backup-to-disk, de-duplication is also in the mix and that's something tar can't do yet. So while you can build a tar-and-bash backup system from scratch without paying a cent, it will be lacking in certain very useful features.
Also? Tar doesn't work nearly as well on Windows.
Your backup system is one area you really do not want to invest a lot of developer creativity. You need it to be bullet proof, fault tolerant, able to handle a variety of data-types, and easy to maintain. Even the commercial packages fail some of these points some of the time, and the home brew systems fall apart much more often relative to these. The big backup boys have agents that allow backups of Oracle DBs, Linux filesystems, Exchange, and Sharepoint all to the same backup system, a home-brew application would have to get very creative to do the same thing; the problem gets even worse when it comes to restore.
Disaster Recovery is another area in which duct tape and bailing wire are to be discouraged most emphatically.
There are battle-tested open-source packages out there that will help with this (DRBD for one), depending on your environment. They're even widely used so finding someone to replace the sysadmin who just had a run in with a city bus is not that hard. Rsync can do a lot as well, so long as the scale is small. Most single systems can have something cobbled together.
Problems arise when you start talking Windows, very complex installations, or money is a major issue. If you throw enough money at a problem, most disaster recovery problems become a lot less complex. There is a lot of industry investment in DR infrastructure, so the tools are out there. Doing it on a shoe-string means that your disaster recovery also hangs by a shoe-string. If you're doing DR just to satisfy your auditors and don't plan on ever actually using it, that's one thing. But if you really expect to recover from a major disaster on that shoe-string you'll be sorely surprised when that string snaps.
Business Continuity is an area where duct tape and bailing wire should be flatly refused.
BC is in many ways DR with a much shorter recovery time. If you had problems getting your DR funded correctly, BC shouldn't even be on the timeline. Again, if it is just so you can check a box on some audit report, that's one thing. Expecting to run on such a rig is quite another.
And finally, if you do end up cobbling together backup, disaster recovery, or business continuity systems from their component parts, testing the system is even more important. In many cases testing DR/BC takes a production outage of some kind, which makes it hard to schedule tests. But testing is the only way to find out if your shoe-string can stand the load.
Tuesday, March 31, 2009
When perfection is the standard
The disaster recovery infrastructure is an area where perfection is the standard, and anything less than perfection is a fault that needs fixing. It shares this distinction with other things like Air Traffic Control and sports officiating. In any area where perfection is the standard, any failure of any kind brings wincing. There are ways to manage around faults, but there really shouldn't be faults in the first place.
In ATC there are constant cross-checks and procedures to ensure that true life-safety faults only happen after a series of faults. In sports officiating, the advent of 'instant replay' rules assist officials in seeing what actually happened from angles other than the ones they saw, all as a way to improve the results. In DR, any time a backup or replication process fails, it leaves an opening through which major data-loss can possibly occur. Each of these have their unavoidable, "Oh *****," moments. Which leads to frustration when it happens too often.
At my old job we had taken some paperwork steps towards documenting DR failures. We didn't have anything like a business-continuity process, but we did have tape backup. When backups failed, there was a form that needed to be filled out and filed, explaining why the fault happened and what can be done to help it not happen again. I filled out a lot of those forms.
Yeah, perfection is the standard for backups. We haven't come even remotely close to perfection for many, many months. Some of it is simple technology faults, like DataProtector and NetWare needing tweaking to talk to each other well or over-used tape drives giving up the ghost and requiring replacement. Some of it is people faults, like forgetting to change out the tapes on Friday so all the weekend fulls fail due to a lack of non-scratch media. Some of it is management process faults, like discovering the sole tape library fell off of support and no one noticed. Some of it is market-place faults, like discovering the sole tape library will be end-of-lifed by the vendor in 10 months. Some of these haven't happened yet, but they are areas that can fail.
If the stimulus fairy visits us, backup infrastructure is top of the list for spending.
In ATC there are constant cross-checks and procedures to ensure that true life-safety faults only happen after a series of faults. In sports officiating, the advent of 'instant replay' rules assist officials in seeing what actually happened from angles other than the ones they saw, all as a way to improve the results. In DR, any time a backup or replication process fails, it leaves an opening through which major data-loss can possibly occur. Each of these have their unavoidable, "Oh *****," moments. Which leads to frustration when it happens too often.
At my old job we had taken some paperwork steps towards documenting DR failures. We didn't have anything like a business-continuity process, but we did have tape backup. When backups failed, there was a form that needed to be filled out and filed, explaining why the fault happened and what can be done to help it not happen again. I filled out a lot of those forms.
Yeah, perfection is the standard for backups. We haven't come even remotely close to perfection for many, many months. Some of it is simple technology faults, like DataProtector and NetWare needing tweaking to talk to each other well or over-used tape drives giving up the ghost and requiring replacement. Some of it is people faults, like forgetting to change out the tapes on Friday so all the weekend fulls fail due to a lack of non-scratch media. Some of it is management process faults, like discovering the sole tape library fell off of support and no one noticed. Some of it is market-place faults, like discovering the sole tape library will be end-of-lifed by the vendor in 10 months. Some of these haven't happened yet, but they are areas that can fail.
If the stimulus fairy visits us, backup infrastructure is top of the list for spending.
Tuesday, February 17, 2009
tsatest and incrementals
Today I learned how to tell TSATEST to do an incremental backup. I also learned that the /path parameter requires the DOS namespace name. Example:
tsatest /V=SHARE: /path=FACILI~1 /U=.username.for.backup /c=2
That'll do an incremental (files with the Archive bit set) backup of that specific directory, on that specific volume.
tsatest /V=SHARE: /path=FACILI~1 /U=.username.for.backup /c=2
That'll do an incremental (files with the Archive bit set) backup of that specific directory, on that specific volume.
Wednesday, February 11, 2009
Performance tuning Data Protector for NetWare
HP Data Protector has a client for NetWare (and OES2, but I'm not backing up any of those yet). This is proving to take a bit of TSA tuning to work out right. I haven't figured out where the problem exactly is, but I've worked around it.
The following settings are what I've got running right now, and seems to work. I may tweak later:
tsafs /readthreadsperjob=1
tsafs /readaheadthrottle=1
This seems to get around a contention issue I'm seeing with more aggressive settings, where the TSAFS memory will go the max allowed by the /cachememorythreshold setting and sit there, not passing data to the DP client. This makes backups go really long. The above setting somehow prevent this from happening.
If these prove stable, I may up the readaheadthrottle setting to see if it halts on that. This is an EVA6100 after all, so I should be able to go up to at least 18 if not 32 for that setting.
The following settings are what I've got running right now, and seems to work. I may tweak later:
tsafs /readthreadsperjob=1
tsafs /readaheadthrottle=1
This seems to get around a contention issue I'm seeing with more aggressive settings, where the TSAFS memory will go the max allowed by the /cachememorythreshold setting and sit there, not passing data to the DP client. This makes backups go really long. The above setting somehow prevent this from happening.
If these prove stable, I may up the readaheadthrottle setting to see if it halts on that. This is an EVA6100 after all, so I should be able to go up to at least 18 if not 32 for that setting.
Tuesday, February 03, 2009
More on DataProtector 6.10
We've had DP6.10 installed for several weeks now and have some experience with it. Yesterday I configured a Linux Installation Server so I can push agents out to Linux hosts without having to go through the truly horrendous install process that DP6.00 forced you to do when not using an Installation Server. This process taught me that DataProtector grew up in the land of UNIX, not Linux.
One of the new features of DP6.10 is that they now have a method for pushing backup agents to Linux/HP-UX/Solaris hosts over SSH. This is very civilized of them. It uses public key and the keychain tool to make it workable.
The DP6.00 method involved tools that make me cringe. Like rlogin/rsh. These are just like telnet in that the username and password is transmitted over the wire in the clear. For several years now we've had a policy in place that states that protocols that require cleartext transmission of security principles like this are not to be used. We are not alone in this. I am very happy HP managed to get DP updated to a 21st century security posture.
Last Friday we also pointed DP at one of our larger volumes on the 6-node cluster. Backup rates from that volume blew our socks off! It pulled data at about 1600GB/Minute (a hair under 27MB/Second). For comparison, SDL320's native transfer rate (the drive we have in our tape library, which DP isn't attached to yet) is 16MB/Second. Considering the 1:1.2 to 1:1.4 compression ratios typical of this sort of file data, the max speed it can back up is still faster than tape.
The old backup software didn't even come close to these speeds, typically running in the 400MB/Min range (7MB/Sec). The difference is that the old software is using straight up TSA, where DP is using an agent. This is the difference an agent makes!
One of the new features of DP6.10 is that they now have a method for pushing backup agents to Linux/HP-UX/Solaris hosts over SSH. This is very civilized of them. It uses public key and the keychain tool to make it workable.
The DP6.00 method involved tools that make me cringe. Like rlogin/rsh. These are just like telnet in that the username and password is transmitted over the wire in the clear. For several years now we've had a policy in place that states that protocols that require cleartext transmission of security principles like this are not to be used. We are not alone in this. I am very happy HP managed to get DP updated to a 21st century security posture.
Last Friday we also pointed DP at one of our larger volumes on the 6-node cluster. Backup rates from that volume blew our socks off! It pulled data at about 1600GB/Minute (a hair under 27MB/Second). For comparison, SDL320's native transfer rate (the drive we have in our tape library, which DP isn't attached to yet) is 16MB/Second. Considering the 1:1.2 to 1:1.4 compression ratios typical of this sort of file data, the max speed it can back up is still faster than tape.
The old backup software didn't even come close to these speeds, typically running in the 400MB/Min range (7MB/Sec). The difference is that the old software is using straight up TSA, where DP is using an agent. This is the difference an agent makes!
Tuesday, January 06, 2009
DataProtector 6.00 vs 6.10
A new version of HP DataProtector is out. One of the nicest new features is that they've greatly optimized the object/session copy speeds.
No matter what you do for a copy, DataProtector will have to read all of one Disk Media (50GB by default) to do the copy. So if you multiplex 6 backups into one Disk Writer device, it'll have to look through the entire media for the slices it needs. If you're doing a session copy, it'll copy the whole session. But object copies have to be demuxed.
DP6.00 did not handle this well. Consistently, each Data Reader device consumed 100% of one CPU for a speed of about 300 MB/Minute. This blows serious chunks, and is completely unworkable for any data-migration policy framework that takes the initial backup to disk, then spools the backup to tape during daytime hours.
DP6.10 does this a lot better. CPU usage is a lot lower, it no longer pegs one CPU at 100%. Also, network speeds vary between 10-40% of GigE speeds (750 to 3000 MB/Minute), which is vastly more reasonable. DP6.10, unlike DP6.00, can actually be used for data migration policies.
No matter what you do for a copy, DataProtector will have to read all of one Disk Media (50GB by default) to do the copy. So if you multiplex 6 backups into one Disk Writer device, it'll have to look through the entire media for the slices it needs. If you're doing a session copy, it'll copy the whole session. But object copies have to be demuxed.
DP6.00 did not handle this well. Consistently, each Data Reader device consumed 100% of one CPU for a speed of about 300 MB/Minute. This blows serious chunks, and is completely unworkable for any data-migration policy framework that takes the initial backup to disk, then spools the backup to tape during daytime hours.
DP6.10 does this a lot better. CPU usage is a lot lower, it no longer pegs one CPU at 100%. Also, network speeds vary between 10-40% of GigE speeds (750 to 3000 MB/Minute), which is vastly more reasonable. DP6.10, unlike DP6.00, can actually be used for data migration policies.
Labels: backup, benchmarking, hp, storage, sysadmin
Friday, September 19, 2008
Moving storage around
The EVA6100 went in just fine with that one hitch I mentioned, and now comes all the work we need to do now that we have actual space again. We're still arguing over how much space to add to which volumes, but once we decide all but Blackboard will be very easy to add.
Blackboard needs more space on both the SQL server and the Content server, and as the Content server is clustered it'll require an outage to manage the increase. And it'll be a long outage, as 300GB of weensy files takes a LONG time to copy. The SQL server uses plain old Basic partitions, so I don't think we can expand that partition, so we may have to do another full LUN copy which will require an outage. That has yet to be scheduled, but needs to happen before we get through much of the quarter.
Over on the EVA4400 side, I'm evacuating data off of the MSA1500cs onto the 4400. Once I'm done with that, I'm going to be:
What has yet to be fully determined is exactly how we're going to use the 4400 in this scheme. I expect to get between 15-20TB of space out of the MSA once I'm done with it, and we have around 20TB on the 4400 for backup. Which is why I'd really like that 40TB license please.
Going Active/Active should do really good things for how fast the MSA can throw data at disk. As I've proven before the MSA is significantly CPU bound for I/O to parity LUNs (Raid5 and Raid6), so having another CPU in the loop should increase write throughput significantly. We couldn't do Active/Active before since you can only do Active/Active in a homogeneous OS environment, and we had Windows and NetWare pointed at the MSA (plus one non-production Linux box).
In the mean time, I watch progress bars. TB of data takes a long time to copy if you're not doing it at the block level. Which I can't.
Blackboard needs more space on both the SQL server and the Content server, and as the Content server is clustered it'll require an outage to manage the increase. And it'll be a long outage, as 300GB of weensy files takes a LONG time to copy. The SQL server uses plain old Basic partitions, so I don't think we can expand that partition, so we may have to do another full LUN copy which will require an outage. That has yet to be scheduled, but needs to happen before we get through much of the quarter.
Over on the EVA4400 side, I'm evacuating data off of the MSA1500cs onto the 4400. Once I'm done with that, I'm going to be:
- Rebuilding all of the Disk Arrays.
- Creating LUNs expressly for Backup-to-Disk functionality.
- Flashing the Active/Active firmware on to it, the 7.00 firmware rev.
- Get the two Backup servers installed with the right MPIO widgetry to take advantage of active/active on the MSA>
What has yet to be fully determined is exactly how we're going to use the 4400 in this scheme. I expect to get between 15-20TB of space out of the MSA once I'm done with it, and we have around 20TB on the 4400 for backup. Which is why I'd really like that 40TB license please.
Going Active/Active should do really good things for how fast the MSA can throw data at disk. As I've proven before the MSA is significantly CPU bound for I/O to parity LUNs (Raid5 and Raid6), so having another CPU in the loop should increase write throughput significantly. We couldn't do Active/Active before since you can only do Active/Active in a homogeneous OS environment, and we had Windows and NetWare pointed at the MSA (plus one non-production Linux box).
In the mean time, I watch progress bars. TB of data takes a long time to copy if you're not doing it at the block level. Which I can't.
Labels: backup, clustering, msa, storage, sysadmin
Tuesday, June 24, 2008
Backing up NSS, note for the future
According to this documentation, the storing of NSS/NetWare metadata in xattrs is turned off by default. You turn it on for OES2 servers through the "nss /ListXattrNWMetadata" command. This allows linux level utilities (i.e. cp, tar) to be able to access and copy the NSS metadata. This also allows backup software that isn't SMS enabled for OES2 to be able to backup the NSS information.
This is handy, as HP DataProtector doesn't support NSS backup on Linux. I need to remember this.
This is handy, as HP DataProtector doesn't support NSS backup on Linux. I need to remember this.
Monday, May 12, 2008
DataProtector 6 has a problem, continued
I posted last week about DataProtector and its Enhanced Incremental Backup. Remember that "enhincrdb" directory I spoke of? Take a look at this:
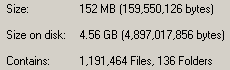
See? This is an in-progress count of one of these directories. 1.1 million files, 152MB of space consumed. That comes to an average file-size of 133 bytes. This is significantly under the 4kb block-size for this particular NTFS volume. On another server with a longer serving enhincrdb hive, the average file-size is 831 bytes. So it probably increases as the server gets older.
On the up side, these millions of weensy files won't actually consume more space for quite some time as they expand into the blocks the files are already assigned to. This means that fragmentation on this volume isn't going to be a problem for a while.
On the down side, it's going to park (in this case) 152MB of data on 4.56GB of disk space. It'll get better over time, but in the next 12 months or so it's still going to be horrendous.
This tells me two things:
Since it is highly likely that I'll be using DataProtector for OES2 systems, this is something I need to keep in mind.
See? This is an in-progress count of one of these directories. 1.1 million files, 152MB of space consumed. That comes to an average file-size of 133 bytes. This is significantly under the 4kb block-size for this particular NTFS volume. On another server with a longer serving enhincrdb hive, the average file-size is 831 bytes. So it probably increases as the server gets older.
On the up side, these millions of weensy files won't actually consume more space for quite some time as they expand into the blocks the files are already assigned to. This means that fragmentation on this volume isn't going to be a problem for a while.
On the down side, it's going to park (in this case) 152MB of data on 4.56GB of disk space. It'll get better over time, but in the next 12 months or so it's still going to be horrendous.
This tells me two things:
- When deciding where to host the enhincrdb hive on a Windows server, format that particular volume with a 1k block size.
- If HP supported NetWare as an Enhanced Incremental Backup client, the 4kb block size of NSS would cause this hive to grow beyond all reasonable proportions.
Since it is highly likely that I'll be using DataProtector for OES2 systems, this is something I need to keep in mind.
Wednesday, May 07, 2008
DataProtecter 6 has a problem
We're moving our BackupExec environment to HP DataProtector. Don't ask why, it made sense at the time.
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers in most need of de-dup technology.
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
- The first level is the mount point. Example: enhincrdb\F\
- The 2nd level are directories named 00-FF which contain the file state data itself
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers in most need of de-dup technology.
Thursday, September 14, 2006
Backups for OES
One of the things that has prevented us from seriously considering a move to OES-Linux has been the backup problem. Apparently there has been some movement on that issue. At Brainshare this year SyncSort was quite prominent in pointing out that they had full support for backing up NSS volumes on Linux.
Today over at Cool Blogs, Richard Jones posted about the progress of this technology in the industry. The short version is that Novell implemented SMS on Linux, and for vendors that already had a solid Linux client it required them to completely rewrite it. Which would explain why it has taken almost two years for the big storage players to come out with supported product. Novell has taken steps to support the really big storage players in UnixLand (IBM, et. al.) in their clients, using extended attributes (Xattrs).
Turns out that xattr thing was slipped into a patch on the 11th of August. I wonder if that's the same package that had shadow volumes included?
Tags: novell, OES
Today over at Cool Blogs, Richard Jones posted about the progress of this technology in the industry. The short version is that Novell implemented SMS on Linux, and for vendors that already had a solid Linux client it required them to completely rewrite it. Which would explain why it has taken almost two years for the big storage players to come out with supported product. Novell has taken steps to support the really big storage players in UnixLand (IBM, et. al.) in their clients, using extended attributes (Xattrs).
Turns out that xattr thing was slipped into a patch on the 11th of August. I wonder if that's the same package that had shadow volumes included?
Tags: novell, OES
Wednesday, June 15, 2005
Veritas Panther
We received a marketing mail from Veritas, hyping the beta for their "panther" product. The boss asked us if we wanted to take a look at it. So I checked it out.
Oy. My verdict? Pointless.
What it is, as distilled from the marketing
Salvage that integrates with your backup system, but for Windows. Since it hooks into the backup system, it has a higher capacity than the Salvage that has been with NetWare since the, oh NW2.1x days in the 80's.
First and foremost, it only works on files kept on Windows servers. Since all of our fileserving is done from NetWare, that means we can't use it for anything but keeping our developers happy, and the lone FrontPage/SharePoint server.
Second, even if it did support NetWare, it doesn't make a lot of sense. NetStorage in NW65SP3 has the ability to salvage files from the web, a key feature of Panther. Changing the low-water mark for when you add storage to your NSS pools is very probably more cost-effective than the Panther product would be. So instead of adding storage when free-space crosses the 15% line, add space when it crosses the 30% line. The extra expense is very probably cheaper than the Veritas product would be.
Oy. My verdict? Pointless.
What it is, as distilled from the marketing
Salvage that integrates with your backup system, but for Windows. Since it hooks into the backup system, it has a higher capacity than the Salvage that has been with NetWare since the, oh NW2.1x days in the 80's.
First and foremost, it only works on files kept on Windows servers. Since all of our fileserving is done from NetWare, that means we can't use it for anything but keeping our developers happy, and the lone FrontPage/SharePoint server.
Second, even if it did support NetWare, it doesn't make a lot of sense. NetStorage in NW65SP3 has the ability to salvage files from the web, a key feature of Panther. Changing the low-water mark for when you add storage to your NSS pools is very probably more cost-effective than the Panther product would be. So instead of adding storage when free-space crosses the 15% line, add space when it crosses the 30% line. The extra expense is very probably cheaper than the Veritas product would be.
Labels: backup
Thursday, December 09, 2004
Backup speeds
The GigE switch is in, the jacks are wired. Now to plug servers into it and see if we get any increased speed out of the thing. I'm hoping we will, but the challenge of getting a new network cable into production systems is a touch tricky. Tonight half our Exchange cluster will land on a server on GigE, which will give us a better idea how I/O vs CPU bound the Exchange backup is.
Labels: backup
Monday, August 30, 2004
Speeeeeed with data!
All values Megs/Minute:
[Using TSAFS]
[Using TSA600]
The format of the test is nodename/volume. Each dataset had more data than known buffers in the data path in an effort to minimize the accelleration gained by such. In most tests, subsequent runs of the same dataset were faster than previous runs due to the caching on the server itself and on the EVA back-end SAN. The data were gathered using the TSATEST shipping in the NW6SP4 service-pack. The FacSrv2 tests are unique in that first User3 was run at 5GB then Share3 was run at 5GB in order to bust buffers where possible. The only variable between datasets was the TSA loaded and any itty bitty file changes that may have happened during normal usage.
What this test clearly shows is that TSAFS is faster than TSA600. In all cases tested the speed-up was north of 200%.
Other observations
One thing I did observe is that the FacSrv servers are faster than the StuSrv servers when it comes to TSA backups. This did merit investigation and I have come to the conclusing that the PSM file used has impacts on speed. Spurious interupts (displayable by "display interupts" from console) increment dramtatically when CPQACPI.PSK (v1.06 5/12/03) is loaded, as it is on the StuSrv-series of servers. The FacSrv series of servers are old enough that they load CPQMPK.PSM instead, and the spurious interupts on those servers are worlds lower than the numbers reported on the StuSrv series. I predict that backup speed improvements are to be had by changing which PSM we load.
It also looked like data characterization played a role in how fast things backed up. User volumes went slower than 'shared' volumes (Class1 is the student version of Share1). This may have something to do with the average file size being smaller on User volumes, or perhaps the churn-rate on the user-volumes leads to noticable fragmentation.
Another test I ran once just because I was curious was to back up Share1 from FacSrv1 and Share3 from FacSrv2 at the same time with TSAFS and monitor the results. Both servers backed up 5GB of data and when they hit the 5GB mark I recorded the rate. When the first server hit that mark I let the backup continue in order to provide the same contentious I/O path for the slower server. The totals were:
FacSrv1/Share1 @ 1862 MB/Min
FacSrv2/Share3 @ 2065 MB/Bin
Aggregate throughput of SAN I/O channel: 3927 MB/Min
This tells me a number of things:
We have some work to do. For one, we need to either get Compaq to address the spurious interupt issue, or drop back to CPQMPK.PSM in order to get good results out of the StuSrv series. Once this is done, I hope that the StuSrv series will be able to provide performance matching or besting that of the older FacSrv line.
The networking infrastructure needs attention. The maximim theoretical throughput for 100Mb ethernet is 750 megs/minute, and each one of the TSAFS backups went faster then that. The maximum speeds observed are fast enough to dent even Gig Ethernet, though at those speeds tape-drive latency comes into play. The current 100Mb connections are not adequate.
The backup server needs to be robust. With the possibility of multiple high-rate streams coming to the server, its own Gig Ethernet connection may become saturated if all four tape-drives are streaming from a fast source. With speeds up that high, PCI-bus contention actually becomes a factor here so the server has to be built with high I/O in mind. No "PC on steroids" here. Best case would be multiple PCI busses, or at the very minimum 64-bit PCI; neither option shows up on sub $2000 hardware.
Our storage back-end is robust. The EVA on the back end can pitch data at amazing speeds. It is very nice to see rates like that, even on volumes that have had 12 months of heavy usage to fragment the bejebers out of them. We can scale this system out a lot further before running into caps.
We need to verify if our backup software solution is compatible with TSAFS. We use BackupExec for Windows, and that answer is not quite clear yet. BackupExec for NetWare is already there, so at least part of the product line knows how to handle it. We need a decision on how to handle open files before progressing on that front. But TSAFS versus BEREMOTE is something I can't test easilly.
TSAFS is the way to go, but it is only one piece of the puzzle.
[Using TSAFS]
| StuSrv1/Stu1
| FacSrv1/Share1 | FacSrv2/User3 | FacSrv2/Share3 | StuSrv2/Class1 |
| 908 | 2106 | 1565 | 2492 | 846 |
| 930 | 2105 | 1536 | 2447 | 885 |
| 925 | 2070 | 1582 | 2519 |
|
[Using TSA600]
| StuSrv1/Stu1 | FacSrv1/Share1 | FacSrv2/User3 | FacSrv2/Share3 | StuSrv2/Class1 |
| 238 | 875 | 625 | 1160 | 221 |
| 265 | 904 | 656 | 1160 | 218 |
| 272 | 895 | 670 | 1184 |
|
| 287 |
|
|
|
|
The format of the test is nodename/volume. Each dataset had more data than known buffers in the data path in an effort to minimize the accelleration gained by such. In most tests, subsequent runs of the same dataset were faster than previous runs due to the caching on the server itself and on the EVA back-end SAN. The data were gathered using the TSATEST shipping in the NW6SP4 service-pack. The FacSrv2 tests are unique in that first User3 was run at 5GB then Share3 was run at 5GB in order to bust buffers where possible. The only variable between datasets was the TSA loaded and any itty bitty file changes that may have happened during normal usage.
What this test clearly shows is that TSAFS is faster than TSA600. In all cases tested the speed-up was north of 200%.
Other observations
One thing I did observe is that the FacSrv servers are faster than the StuSrv servers when it comes to TSA backups. This did merit investigation and I have come to the conclusing that the PSM file used has impacts on speed. Spurious interupts (displayable by "display interupts" from console) increment dramtatically when CPQACPI.PSK (v1.06 5/12/03) is loaded, as it is on the StuSrv-series of servers. The FacSrv series of servers are old enough that they load CPQMPK.PSM instead, and the spurious interupts on those servers are worlds lower than the numbers reported on the StuSrv series. I predict that backup speed improvements are to be had by changing which PSM we load.
It also looked like data characterization played a role in how fast things backed up. User volumes went slower than 'shared' volumes (Class1 is the student version of Share1). This may have something to do with the average file size being smaller on User volumes, or perhaps the churn-rate on the user-volumes leads to noticable fragmentation.
Another test I ran once just because I was curious was to back up Share1 from FacSrv1 and Share3 from FacSrv2 at the same time with TSAFS and monitor the results. Both servers backed up 5GB of data and when they hit the 5GB mark I recorded the rate. When the first server hit that mark I let the backup continue in order to provide the same contentious I/O path for the slower server. The totals were:
FacSrv1/Share1 @ 1862 MB/Min
FacSrv2/Share3 @ 2065 MB/Bin
Aggregate throughput of SAN I/O channel: 3927 MB/Min
This tells me a number of things:
- Parallel backups won't drop absolute performance below the rated tape-drive performance spec
- The SAN storage really is fast
- A third stream (Share2?) could be added and still probably maintain real-world network speeds.
We have some work to do. For one, we need to either get Compaq to address the spurious interupt issue, or drop back to CPQMPK.PSM in order to get good results out of the StuSrv series. Once this is done, I hope that the StuSrv series will be able to provide performance matching or besting that of the older FacSrv line.
The networking infrastructure needs attention. The maximim theoretical throughput for 100Mb ethernet is 750 megs/minute, and each one of the TSAFS backups went faster then that. The maximum speeds observed are fast enough to dent even Gig Ethernet, though at those speeds tape-drive latency comes into play. The current 100Mb connections are not adequate.
The backup server needs to be robust. With the possibility of multiple high-rate streams coming to the server, its own Gig Ethernet connection may become saturated if all four tape-drives are streaming from a fast source. With speeds up that high, PCI-bus contention actually becomes a factor here so the server has to be built with high I/O in mind. No "PC on steroids" here. Best case would be multiple PCI busses, or at the very minimum 64-bit PCI; neither option shows up on sub $2000 hardware.
Our storage back-end is robust. The EVA on the back end can pitch data at amazing speeds. It is very nice to see rates like that, even on volumes that have had 12 months of heavy usage to fragment the bejebers out of them. We can scale this system out a lot further before running into caps.
We need to verify if our backup software solution is compatible with TSAFS. We use BackupExec for Windows, and that answer is not quite clear yet. BackupExec for NetWare is already there, so at least part of the product line knows how to handle it. We need a decision on how to handle open files before progressing on that front. But TSAFS versus BEREMOTE is something I can't test easilly.
TSAFS is the way to go, but it is only one piece of the puzzle.
Labels: backup
Friday, August 27, 2004
Speeeeeeed
Backing Up Vol: SHARE1:Holy fiber channel, Batman! I've never seen a stream go that fast. This is a TSATEST backup using TSAFS (TSA600 was giving me still-impressive numbers around 900 MB/min for this dataset), with an EVA300 back-end.
Read Count: 90253
Last Read Size: 17566
Total Bytes Read: 4664767995
Raw Data MB/min: 2231.01
Backup Sets: 26424
Ave. Open Time: 000uss
Ave. Close Time: 000us
Effective MB/min: 2183.85
Labels: backup
Tuesday, August 10, 2004
Lice-ridden backups
There is a reason I hate them.
I hate them because if they fail, we have a hole that we hope no one notices.
I hate them because they can always be a little faster than they have been going.
I hate them because they take too many tapes.
I hate them because the backup agents never perform the way I NEED them to.
I hate them because two otherwise identical servers can back-up at completely different speeds.
I hate them because we never have enough time to get them all in.
I hate them because we can never leverage the resources we need to get the damned things to work well.
I hate them because our backup server is a homebrew frankenstien that probably can't keep up with the brand spanking new tape library.
And most of all, I hate them because we get to manage the backup infrastructure with no budget of our own.
I hate them because if they fail, we have a hole that we hope no one notices.
I hate them because they can always be a little faster than they have been going.
I hate them because they take too many tapes.
I hate them because the backup agents never perform the way I NEED them to.
I hate them because two otherwise identical servers can back-up at completely different speeds.
I hate them because we never have enough time to get them all in.
I hate them because we can never leverage the resources we need to get the damned things to work well.
I hate them because our backup server is a homebrew frankenstien that probably can't keep up with the brand spanking new tape library.
And most of all, I hate them because we get to manage the backup infrastructure with no budget of our own.
Labels: backup
Wednesday, August 04, 2004
Backup fun, again
No crashes last night! I have hopes that the newer code is doing its job. Some of the incrementals are taking way too long, so I changed one of them to Full since its taking that long anyway. We'll see tonight how things go.
So far, so good!
So far, so good!
Labels: backup
Tuesday, August 03, 2004
Backup fun
The backup fun continues. Had a few more crashes last night, and this has now reached a big problem.
It turns out that there are a few others folk out there who are experiencing crashes on their clusters when TSAFS is loaded. Interesting, thought I. In my pre-incident checkout, I found that Novell has some newer TSA's than what I have loaded. Rather than burn an incident to get told, "update, you idiot," I updated. We'll see how things run tonight.
http://support.novell.com/cgi-bin/search/searchtid.cgi?/2969042.htm
The TID doesn't have the list of issues, but here is an extract of some of the neat stuff this update does:
TSAFS:
7. TSAFS was limited to 1024 bytes for the path names. This limitation has been
removed.
10. Fixed a problem with remote selective restores. An error would be returned:
"Could not connect to the TSA. Check the TSA is loaded correctly
SMDR : The required entry for protocol or service is not found.
Register appropriate protocol or service."
11.Fixed some pagefault processor abends.
13. Fixed a problem where ACCESS DENIED errors were returned backing up certain
directories. This happend because the zOpen used by SMS is requesting read access to
any object and the starting point for the backup is a location that the
specified user has visibility in but no read access.
16. fixes the invalid name parameters that caused abends. This was due to invalid
data structures that were being passed into tsafs.nlm. They were in the wrong
format.
17. Fixed abends that would result if the server was in an out of memory condition.
This was caused by the tsafs.nlm read ahead cache pointer that was getting
messed up. Check the server to see if it's getting low on ram.
19. Fixed abends in tsafs doing restores
TSA600:
2. Fixes a problem with the archive bit not being cleared. This would result
in too much data being backed up.
3. Fixed a problem with the tsa600.nlm leaking memory on restores and copies
because RestoreFullPaths was not calling Free.
7. Fixed abend problems with the tsas amd smdr
10. Fixed problems with slow incremental backups. The full backups would be fast.
Only the incrementals would be slow.
SMDR:
1. IPX dependency of SMDR removed. [YAY!]
13. Smdr has been enhanced to resolve the server/cluster poolname to an ip
address thru the sys:etc\hosts file.
14. IP address mgmt support added.
17. SMDR has been modified so that it does not need to parse the SYS:ETC\HOSTS file on it own.
It uses the gethostbyname() function to do that. In addition, this method
expands its name resolution to use DNS as well.
It turns out that there are a few others folk out there who are experiencing crashes on their clusters when TSAFS is loaded. Interesting, thought I. In my pre-incident checkout, I found that Novell has some newer TSA's than what I have loaded. Rather than burn an incident to get told, "update, you idiot," I updated. We'll see how things run tonight.
http://support.novell.com/cgi-bin/search/searchtid.cgi?/2969042.htm
The TID doesn't have the list of issues, but here is an extract of some of the neat stuff this update does:
TSAFS:
7. TSAFS was limited to 1024 bytes for the path names. This limitation has been
removed.
10. Fixed a problem with remote selective restores. An error would be returned:
"Could not connect to the TSA. Check the TSA is loaded correctly
SMDR : The required entry for protocol or service is not found.
Register appropriate protocol or service."
11.Fixed some pagefault processor abends.
13. Fixed a problem where ACCESS DENIED errors were returned backing up certain
directories. This happend because the zOpen used by SMS is requesting read access to
any object and the starting point for the backup is a location that the
specified user has visibility in but no read access.
16. fixes the invalid name parameters that caused abends. This was due to invalid
data structures that were being passed into tsafs.nlm. They were in the wrong
format.
17. Fixed abends that would result if the server was in an out of memory condition.
This was caused by the tsafs.nlm read ahead cache pointer that was getting
messed up. Check the server to see if it's getting low on ram.
19. Fixed abends in tsafs doing restores
TSA600:
2. Fixes a problem with the archive bit not being cleared. This would result
in too much data being backed up.
3. Fixed a problem with the tsa600.nlm leaking memory on restores and copies
because RestoreFullPaths was not calling Free.
7. Fixed abend problems with the tsas amd smdr
10. Fixed problems with slow incremental backups. The full backups would be fast.
Only the incrementals would be slow.
SMDR:
1. IPX dependency of SMDR removed. [YAY!]
13. Smdr has been enhanced to resolve the server/cluster poolname to an ip
address thru the sys:etc\hosts file.
14. IP address mgmt support added.
17. SMDR has been modified so that it does not need to parse the SYS:ETC\HOSTS file on it own.
It uses the gethostbyname() function to do that. In addition, this method
expands its name resolution to use DNS as well.
Labels: backup
Wednesday, June 09, 2004
Backup speeds
They managed to find the correct combination of driver and voodoo and things are now talking. He was chorteling over a 700 mb/min backup speed earlier, of which I fully understand. When you've been looking at backups that barely peak over 200 megs/minute, seeing one spew forth at 700 megs a minute is cause for giggling with glee. And seeing a Verify go at 1600 megs/minute is cause for laughing out loud with joy.
Depending on how things go, we may end up picking up the fibre-channel interface for the Scalar. It'll allow our backups to stream that much faster, plus allow for future expansion in the backup-heads. The server that is driving it right now is a wee bit under-powered when it comes to PCI bus, so we'll start bottlenecking well before we hit the theoretical limits on dual GigE ports.
Depending on how things go, we may end up picking up the fibre-channel interface for the Scalar. It'll allow our backups to stream that much faster, plus allow for future expansion in the backup-heads. The server that is driving it right now is a wee bit under-powered when it comes to PCI bus, so we'll start bottlenecking well before we hit the theoretical limits on dual GigE ports.
Labels: backup
Friday, March 12, 2004
Tonight's backup tapes have been changed around. And I found out that an abend on one of the servers will prevent backup processing until we get reboots. Not like I haven't done thousands of those over the years. Aie. This is why I don't run backup software (except for agents) on servers that have anything resembling uptime requirements.
Labels: backup
![]()
