Wednesday, February 11, 2009
High availability
Disclaimer: Due to the budget crisis, it is very possible we will not be able to replace the cluster nodes when they turn 5 years old. It may be easier to justify eating the greatly increased support expenses. Won't know until we try and replace them. This is a pure fantasy exercise as a result.
The stats of the 6-node cluster are impressive:
- 12 P4 cores, with an average of 3GHz per core (36GHz).
- A total of 24GB of RAM
- About 7TB of active data
- HP ProLiant DL580 (4 CPU sockets)
- 4x Quad Core Xeon E7330 Processors (2.40GHz per core, 38.4GHz total)
- 24 GB of RAM
- The usual trimmings
- Total cost: No more than $16,547 for us
A single server does have a few things to recommend it. By doing away with the virtual servers, all of the NCP volumes would be hosted on the same server. Right now each virtual-server/volume pair causes a new connection to each cluster node. Right now if I fail all the volumes to the same cluster node, that cluster node will legitimately have on the order of 15,000 concurrent connections. If I were to move all the volumes to a single server itself, the concurrent connection count would drop to only ~2500.
Doing that would also make one of the chief annoyances of the Vista Client for Novell much less annoying. Due to name cache expiration, if you don't look at Windows Explorer or that file dialog in the Vista client once every 10 minutes, it'll take a freaking-long time to open that window when you do. This is because the Vista client has to enumerate/resolve the addresses of each mapped drive. Because of our cluster, each user gets no less than 6 drive mappings to 6 different virtual servers. Since it takes Vista 30-60 seconds per NCP mapping to figure out the address (it has to try Windows resolution methods before going to Novell resolution methods, and unlike WinXP there is no way to reverse that order), this means a 3-5 minute pause before Windows Explorer opens.
By putting all of our volumes on the same server, it'd only pause 30-60 seconds. Still not great, but far better.
However, putting everything on a single server is not what you call "highly available". OES2 is a lot more stable now, but it still isn't to the legendary stability of NetWare 3. Heck, NetWare 6.5 isn't at that legendary stability either. Rebooting for patches takes everything down for minutes at a time. Not viable.
With a server this beefy it is quite doable to do a cluster-in-a-box by way of Xen. Lay a base of SLES10-Sp2 on it, run the Xen kernel, and create four VMs for NCS cluster nodes. Give each 64-bit VM 7.75GB of RAM for file-caching, and bam! Cluster-in-a-box, and highly available.
However, this is a pure fantasy solution, so chances are real good that if we had the money we would use VMWare ESX instead XEN for the VM. The advantage to that is that we don't have to keep the VM/Host kernel versions in lock-step, which reduces downtime. There would be some performance degradation, and clock skew would be a problem, but at least uptime would be good; no need to perform a CLUSTER DOWN when updating kernels.
Best case, we'd have two physical boxes so we can patch the VM host without having to take every VM down.
But I still find it quite interesting that I could theoretically buy a single server with the same horsepower as the six servers driving our cluster right now.
Labels: hp, linux, netware, novell, NSS, OES, sysadmin, virtualization
Wednesday, December 03, 2008
OES2 SP1 ships!
It's out!
Tuesday, June 24, 2008
Backing up NSS, note for the future
This is handy, as HP DataProtector doesn't support NSS backup on Linux. I need to remember this.
Monday, June 16, 2008
A good article on trustees
Labels: coolsolutions, edir, netware, novell, NSS, storage, sysadmin
Wednesday, May 14, 2008
NetWare and Xen
Guidelines for using NSS in a virtual environment
Towards the bottom of this document, you get this:
Nice stuff there! The "xenblk barriers" can also have an impact on the performance of your virtualized NetWare server. If your I/O stream runs the server out of cache, performance can really suffer if barriers are non-zero. If it fits in cache, the server can reorder the I/O stream to the disks to the point that you don't notice the performance hit.Configuring Write Barrier Behavior for NetWare in a Guest Environment
Write barriers are needed for controlling I/O behavior when writing to SATA and ATA/IDE devices and disk images via the Xen I/O drivers from a guest NetWare server. This is not an issue when NetWare is handling the I/O directly on a physical server.
The XenBlk Barriers parameter for the SET command controls the behavior of XenBlk Disk I/O when NetWare is running in a virtual environment. The setting appears in the Disk category when you issue the SET command in the NetWare server console.
Valid settings for the XenBlk Barriers parameter are integer values from 0 (turn off write barriers) to 255, with a default value of 16. A non-zero value specifies the depth of the driver queue, and also controls how often a write barrier is inserted into the I/O stream. A value of 0 turns off XenBlk Barriers.
A value of 0 (no barriers) is the best setting to use when the virtual disks assigned to the guest server’s virtual machine are based on physical SCSI, Fibre Channel, or iSCSI disks (or partitions on those physical disk types) on the host server. In this configuration, disk I/O is handled so that data is not exposed to corruption in the event of power failure or host crash, so the XenBlk Barriers are not needed. If the write barriers are set to zero, disk I/O performance is noticeably improved.
Other disk types such as SATA and ATA/IDE can leave disk I/O exposed to corruption in the event of power failure or a host crash, and should use a non-zero setting for the XenBlk Barriers parameter. Non-zero settings should also be used for XenBlk Barriers when writing to Xen LVM-backed disk images and Xen file-backed disk images, regardless of the physical disk type used to store the disk images.
So, keep in mind where your disk files are! If you're using one huge XFS partition and hosting all the disks for your VM-NW systems on that, then you'll need barriers. If you're presenting a SAN LUN directly to the VM, then you'll need to "SET XENBLK BARRIERS = 0", as they're set to 16 by default. This'll give you better performance.
Labels: benchmarking, netware, novell, NSS, OES, storage, virtualization
Monday, May 12, 2008
DataProtector 6 has a problem, continued
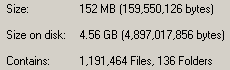
See? This is an in-progress count of one of these directories. 1.1 million files, 152MB of space consumed. That comes to an average file-size of 133 bytes. This is significantly under the 4kb block-size for this particular NTFS volume. On another server with a longer serving enhincrdb hive, the average file-size is 831 bytes. So it probably increases as the server gets older.
On the up side, these millions of weensy files won't actually consume more space for quite some time as they expand into the blocks the files are already assigned to. This means that fragmentation on this volume isn't going to be a problem for a while.
On the down side, it's going to park (in this case) 152MB of data on 4.56GB of disk space. It'll get better over time, but in the next 12 months or so it's still going to be horrendous.
This tells me two things:
- When deciding where to host the enhincrdb hive on a Windows server, format that particular volume with a 1k block size.
- If HP supported NetWare as an Enhanced Incremental Backup client, the 4kb block size of NSS would cause this hive to grow beyond all reasonable proportions.
Since it is highly likely that I'll be using DataProtector for OES2 systems, this is something I need to keep in mind.
Wednesday, May 07, 2008
DataProtecter 6 has a problem
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
- The first level is the mount point. Example: enhincrdb\F\
- The 2nd level are directories named 00-FF which contain the file state data itself
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers in most need of de-dup technology.
Thursday, March 20, 2008
BrainShare Thursday
- Novell Open Enterprise Server 2 Interoperability with Windows and AD. All about Domain Services for Windows and Samba. Neither of which we'll ever use. No idea why I wanted to be in this session.
- Rapid Deployment of ZENworks Configuration Management. Other people around here have suggested that if we haven't moved yet, wait until at least SP3 before moving. If then. So, demotivated. Plus I was rather tired.
- Configuring Samba on OES2. CIFS will do what we need, I don't need Samba. Don't need this one. Skipped.
BASH tips and tricks. I got a lot out of it, but the developers around me were quietly derisive.
ZEN Overview and Features
Not so much with the futures, but it did explain Novell's overall ZEN strategy. It isn't a coincidence that most of Novell's recent purchases have been for ZEN products.
TUT303: OES2 Clusters, from beginning to extremes
This was great. They had a full demo rig, and they showed quite a bit in it. Including using Novell Cluster Services to migrate Xen VM's around. They STRONGLY recommended using AutoYast to set up your cluster nodes to ensure they are simply identical except for the bits you explicitly want different (hostname, IP). And also something else I've heard before, you want one LUN for each NSS Pool. Really. Plus, the presenters were rather funny. A nice cap for the day.
And tonight, Meet the Experts!
Labels: brainshare, clustering, linux, novell, NSS, OES, storage, zenworks
Friday, January 11, 2008
Disk-space over time
To show you what I'm talking about, I'm going to post a chart based on the student-home-directory data. We have three home-directory volumes for students, which run between 7000-8000 home directories on them. We load-balance by number of directories rather than least-size. The chart:
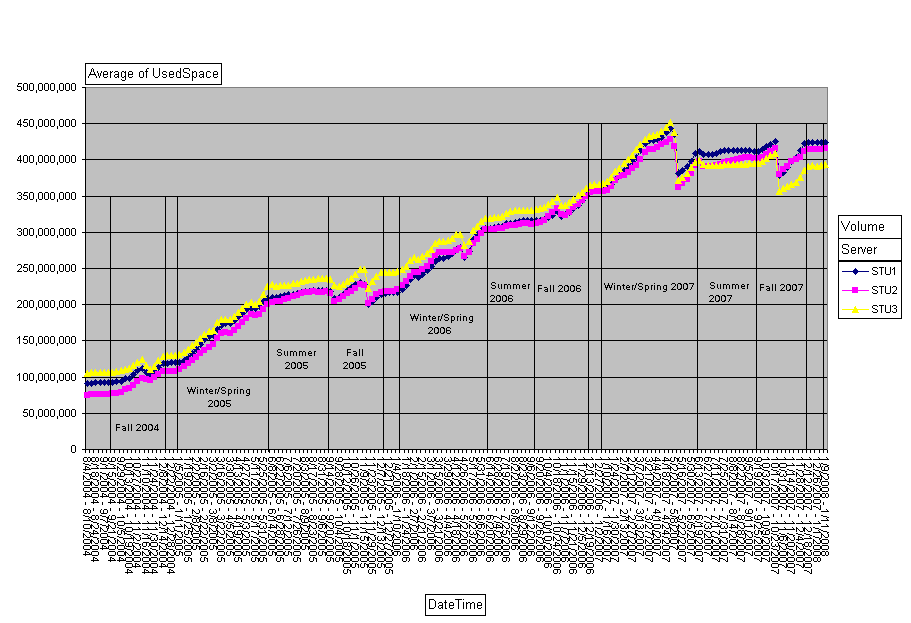
As you can see, I've marked up our quarters. Winter/Spring is one segment on this chart since Spring Break is hard to isolate on these scales. We JUST started Winter 2008, so the last dot on the chart is data from this week. If you squint in (or zoom in like I can) you can see that last dot is elevated from the dot before it, reflecting this week's classes.
There are several sudden jumps on the chart. Fall 2005. Spring 2005. Spring 2007 was a big one. Fall 2007 just as large. These reflect student delete processes. Once a student hasn't been registered for classes for a specified period of time (I don't know what it is off hand, but I think 2 terms) their account goes on the 'ineligible' list and gets purged. We do the purge once a quarter except for Summer. The Fall purge is generally the biggest in terms of numbers, but not always. Sometimes the number of students purged is so small it doesn't show on this chart.
We do get some growth over the summer, which is to be expected. The only time when classes are not in session is generally from the last half of August to the first half of September. Our printing volumes are also w-a-y down during that time.
Because the Winter purge is so tiny, Winter quarter tends to see the biggest net-gain in used disk-space. Fall quarter's net-gain sometimes comes out a wash due to the size of that purge. Yet if you look at the slopes of the lines for Fall, correcting for the purge of course, you see it matches Winter/Spring.
Somewhere in here, and I can't remember where, we increased the default student directory-quota from 200MB to 500MB. We've found Directory Quotas to be a much better method of managing student directory sizes than User Quotas. If I remember my architectures right, directory quotas are only possible because of how NSS is designed.
If you take a look at the "Last Modified Times" chart in the Volume Inventory for one of the student home-directory volumes you get another interesting picture:
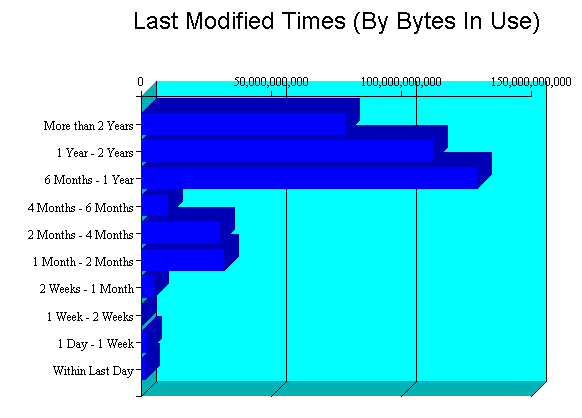
We have a big whack of data aged 12 months or newer. That said, we have non-trivial amounts of data aged 12 months or older. This represents where we'd get big savings when we move to OES2 and can use Dynamic Storage Technology (formerly known as 'shadowvolumes'). Because these are students and students only stick around for so long, we don't have a lot of stuff in the "older than 2 years" column that is very present on the Faculty/Staff volumes.
Being the 'slow, cheap,' storage device is a role well suited to the MSA1500 that has been plaguing me. If for some reason we fail to scare up funding to replace our EVA3000 with another EVA less filled-to-capacity, this could buy a couple of years of life on the EVA3000. Unfortunately, we can't go to OES2 until Novell ships an edirectory enabled AFP server for Linux, currently scheduled for late 2008 at the earliest.
Anyway, here is some insight into some of our storage challenges! Hope it has been interesting.
Monday, April 02, 2007
Concurrency, again
Some typical results, units are in KB/s
| Initial write | 11058.47 | |
| Rewrite | 11457.83 | |
| Read | 5896.23 | |
| Re-read | 5844.52 | |
| Reverse Read | 6395.33 | |
| Stride read | 5988.33 | |
| Random read | 6761.84 | |
| Mixed workload | 8713.86 | |
| Random write | 7279.35 |
Consistantly, write performance is better than read performance. On the tests that are greatly benefitted by caching, reverse read and stride read, performance was quite acceptable. All nine machines wrote at near flank speed for 100MB ethernet, which means that the 1GB link the server was plugged in to was doing quite a bit of work during the Initial Write stage.
What is perhaps the most encouraging is that CPU loading on the server itself stayed below the saturation level. Having spoken with some of the engineers who write this stuff, this is not surprising. They've spent a lot of effort in making sure that incoming requests can be fulfilled from cache and not go to disk. Going to disk is more expensive in Linux than in NetWare due to architectural reasons. Had the working set been 4GB or larger I strongly suspect that CPU loading would have been significantly higher. Unfortunately, as school is back in session I can't 'borrow' that lab right now as the tests themselves consume 100% of the resources on the workstations. Students would notice that.
The next step for me is to see if I can figure out how large the 'working set' of open files on FacShare is. If it's much bigger than, say, 3.2GB we're going to need new hardware to make OES work for us. This won't be easy. A majority of the size of the open files are outlook archives (.PST files) for Facilities Management. PST files are low performance critters, so I don't care if they're slow. I do care about things like access databases, though, so figuring out what my 'active set' actually is will take some figuring.
Long story short: With OES2 and 64 bit hardware, I bet I could actually use a machine with 18GB of RAM!
Labels: benchmarking, novell, NSS, OES
Thursday, March 29, 2007
Why cache is good
One test I did underlines the need to tune your cache correctly. Using the same iozone tool I've used in the past, I ran the throughput test with multiple threads. Three tests:
20 threads processing against a separate 100MB file (2GB working set)
40 threads processing against a separate 100MB file (4GB working set)
20 threads processing against a separate 200MB file (4GB working set)
The server I'm playing with is the same one I used in September. It is running OES SP2, patched as of a few days ago. 4GB of RAM, and 2x 2.8 P4 CPU's. The data volume is on the EVA 3000 on a Raid0 partition. I'm testing OES througput not the parity performance of my array. Due to PCI memory, effective memory is 3.2GB. Anyway, the very good table:
20x100M 40x100M 20x200MThe 2GB dataset fit inside of memory. You can see the performance boost that provides on each of the Read tests. It is especially significant on the tests designed to bust read-ahead optimization such as Reverse Read, Stride Read, and Random Read. The Mixed Workload test showed it as well.
Initial write 12727.29193 12282.03964 12348.50116
Rewrite 11469.85657 10892.61572 11036.0224
Read 17299.73822 11653.8652 12590.91534
Re-read 15487.54584 13218.80331 11825.04736
Reverse Read 17340.01892 2226.158993 1603.999649
Stride read 16405.58679 1200.556759 1507.770897
Random read 17039.8241 1671.739376 1749.024651
Mixed workload 10984.80847 6207.907829 6852.934509
Random write 7289.342926 6792.321884 6894.767334
One thing that has me scratching my head is why Stride Read is so horrible with the 4GB data-sets. By my measure about 2.8GB of RAM should be available for caching, so most of the dataset should fit into cache and therefore turn in the fast numbers. Clearly, something else is happening.
Anyway, that is why you want to have a high cache-hit percentage on your NSS cache. This is also why 64-bit memory will help you if you have very large working sets of data that your users are playing on, and we're getting to the level where 64-bit will help. And will help even though OES NCP doesn't scale quite as far as we'd like it to. That's the overall question I'm trying to answer here.
Labels: benchmarking, novell, NSS, OES, storage
Tuesday, March 20, 2007
TUT212: Novell Storage Services
- Three times the NSS source tree has been accidentally deleted by developers. It has been restored from Salvage each time. Go Salvage.
- When mounting NSS on OES-Linux, mount it with the long namespace. Saves time. I did not catch the fstab option to make this work, though.
- You can create NSS pools that are not NetWare compatible
- NSS & LUM
- NSS = 128-bit, Unix = 32-bit. LUM handles the translations.
- Users need to be LUM-enabled for this to work
- NCP-Serv can fake it for non-LUM users, but it is slower access.
- OES1 = Rights and owners set all posix
- OES2 = Rights and owners set through extended attributes
- If Samba, then LUM.
- Trustees are enforced, GUID is ignored.
- Beasts = inodes!
- /proc/slabinfo -> lsa_inode_cache = @ of inodes/files in cache
- On NetWare, memory over the 4GB line is treated as a RAMdisk for files over 128K in size.
- 32-bit vs 64-bit linux & NSS
- 32-bit linux: 1GB max kernel memory, makes for tricky caching
- 64-bit linux: All memory can be kernel memory
- NSS patch in mid-December allowed meta-data caching in user-memory, greatly speeding up meta-data reads on 32-bit systems with large numbers of files.
- nss /HighMemoryCacheType= [private|linux|none]
- Sets the use of User memory in 32-bit OES
- None = Use the same algorithm as OES-FCS, which is to try and cache everything in Kernel-mode memory. Only option on 64-bit linux since it doesn't have to use USER memory at all.
- linux = integrate caching into the regular linux caches. This can be a problem on dual use file-server/app-server system, as memory hungry applications can cause the file-system cache to purge completely.
- private = set up a separate user-mode cache in memory outside of the linux cache. Best for dedicated file-servers.
Labels: brainshare, NSS, OES
Wednesday, October 11, 2006
NSS read-ahead
nss /AllocAheadBlks=[vol]:[count]
nss /ReadAheadBlks=[vol]:[count]
AllocAhead allocates blocks on writes, where ReadAhead is just that, blocks read ahead of the read. Both behaviors are to make access to the base I/O subsystem more efficient and to improve Read performance.
By default as of NetWare 6.5, the default ReadAhead is 2 blocks (8KB), and the default AllocAhead is 15 blocks (60KB).
So what is the recommended settings for these? The manual has this to say:
The most efficient value for block count depends on your hardware. In general, we recommend a block count of 8 to 16 blocks for large data reads; 2 blocks for CDs, 8 blocks for DVDs, and 2 blocks for ZLSS.ZLSS is, I believe, a standard volume.
The question then begs what is the real optimal setting for this, based on what you can find out about your storage systems. I don't know, but I do have some suggestive ideas. If I have time, I'll see what I can do about testing it.
The gold standard is having very good data on how I/O is performed on your volume. For a volume consisting of mostly databases, such as Access files, the read-ahead should be set to a value close to the average record-read size. For a plain ole home-directory volume file size is probably the better determiner of 'best'.
Running some stats on the STU1 volume, I've found the following:
RAID Stripe size: 128KB
NSS Block size: 4KB
Median Size: 8192KB
Average Size: 293KB
File-count Median Size: 16KB
- 50% of the files on STU1 are 16K or smaller
- 50% of the files on STU1 are responsible for 0.55% of the total space used on STU1
- 90% of the files on STU1 are 256K or smaller, which represents 7.9% of the total space used on STU1
- 10% of the files on STU1 are responsible for over 90% of the data on STU1
The GIS volume is another story.
Median Size: 200MB
Average Size: 11.5MB
File-count Median Size: 8KB
- Total files on the volume is vastly smaller than on STU1
- 43% of the data on the GIS volume are in files larger than 256MB
- The largest file-type is TIF, which is an uncompressed graphics format that is read as a whole, not as sub-records
- Files under 64MB in size represent 93% of the files, but only 7.7% of the data. Compare that with 99.97% and 89.3% respectively on STU1
Tags: OES, NSS
![]()
