For many reasons, discussions at work have turned to recovering/handling layoffs. A coworker asked a good question:
Have you ever seen a company culture recover after things went bad?
I have to say no, I haven't. To unpack this a bit, what my coworker was referring to is something loooong time readers of my blog have seen me talk about before, budget problems. What happens to a culture when the money isn't there, and then management starts cutting jobs?
In the for-profit sector of American companies, you get a heck of a lot of trauma from the sudden-death style layoffs (or to be technical reductions in force because there is no call-back mechanism in the SaaS industry). Sudden loss of coworkers with zero notice, scrambling to cover for their work, scrambling to deal with the flash reorganization that almost always comes with a layoff, scrambling to worry about if you'll be next, it all adds up to a lot of insecurity in the workplace. Or a lack of psychological safety, and I've talked about what happens then.
This coworker was also asking about some of the other side effects of a chronic budget crunch. For publicly traded companies, you can enter this budget crunch well before actual cashflow is a problem due to the forcing effects of the stock market. Big Tech is doing a lot of layoffs right now, but nearly every one of the majors is still profitable, just not profitable enough for the stock market. Living inside one of these companies means dealing with layoffs, but also things like:
- Travel budget getting hard to approve, as they crank down spend.
- Back-filling departures takes much longer, if you get it at all.
- Not getting approval to hire people to fill needs.
- Innovation pressure: have to hit bolder targets with the same resources, and the same overhead.
- Adding a new SaaS vendor becomes nearly impossible.
- Changing the performance review framework to emphasize "business value" over "growth".
- Reduced support for employee groups like those supporting disabled and racial employees.
- Reorgs. So many reorgs.
- Hard turns on long term strategy.
If a company hasn't had to live through this before the culture doesn't yet bear the scars. The employees certainly do, especially those of us who were in the market in 2007-2011. Many of us left companies to get away from this kind of thing. That said, the last major down period in tech was over ten years ago; there are a lot of people in the market right now who've never seen it get actually bad for a long period of time. "Crypto Winter", the fall of many crypto-currency based companies, was as close as we've gotten as an industry.
When the above trail of suck starts happening in a company that hasn't had to live through it before, it leaves scar tissue. The scars are represented by the old-timers, who remember what upper management is like when the financial headwinds are blowing strong enough. The old salts never regain their trust of upper management, because they know first-hand that they're face eating leopards.
Even if upper management turns the milk and honey taps on, brings out the bread and circuses, and undoes all the list-of-suck from above, the old-timers (which means the people in middle management or senior IC roles) will still remember upper management is capable of much worse. That changes a culture. As I talked about before, trust is never full again, it's always conditional.
So no, it'll never go back to the way it was before. New people may think so, but the old timers will know otherwise.
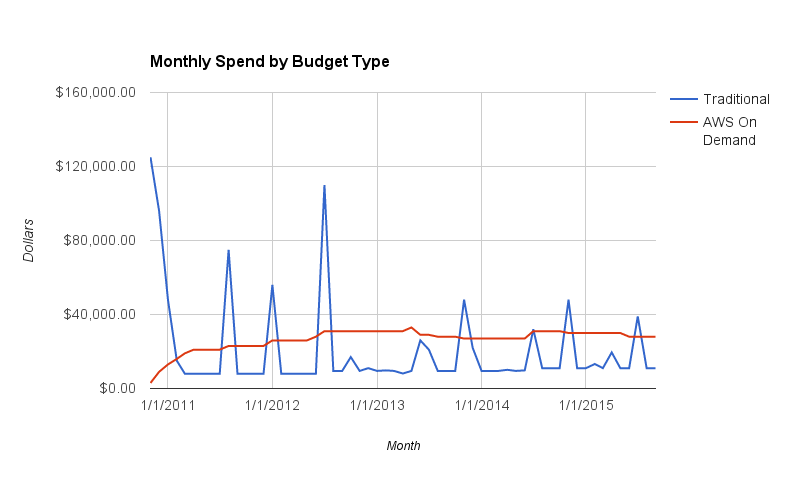 The AWS line actually results in more money over time, as AWS does a good job of capturing costs that the traditional method generally ignores or assumes is lost in general overhead. But the screaming doesn't happen at the end of four years when they run the numbers, it happens in month four when the ongoing operational spend after build-out is done is w-a-y over what it used to be.
The AWS line actually results in more money over time, as AWS does a good job of capturing costs that the traditional method generally ignores or assumes is lost in general overhead. But the screaming doesn't happen at the end of four years when they run the numbers, it happens in month four when the ongoing operational spend after build-out is done is w-a-y over what it used to be.