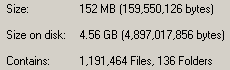
I deal with some large file-systems. Because of what we do, we get shipped archives with a lot of data in them. Hundreds of gigs sometimes. These are data provided by clients for processing, which we then do. Processing sometimes doubles, or even triples or more, the file-count in these filesystems depending on what our clients want done with their data.
One 10GB Outlook archive file can contain a huge number of emails. If a client desires these to be turned into .TIFF files for legal processes, that one 10GB .pst file can turn into hundreds of thousands of files, if not millions.
I've had cause to change some permissions at the top of some of these very large filesystems. By large, I mean larger than the big FacShare volume at WWU in terms of file-counts. As this is on a Windows NTFS volume, it has to walk the entire file-system to update permissions changes at the top.
This isn't the exact problem I'm fixing, but it's much like in some companies where granting permissions to specific users is done instead of to groups, and then that one user goes elsewhere and suddenly all the rights are broken and it takes a day and half to get the rights update processed (and heaven help you if it stops half-way for some reason).
Big file-systems take a long time to update rights inheritance. This has been a fact of life on Windows since the NT days. Nothing new here.
But... it doesn't have to be this way. I explain under the cut.
One 10GB Outlook archive file can contain a huge number of emails. If a client desires these to be turned into .TIFF files for legal processes, that one 10GB .pst file can turn into hundreds of thousands of files, if not millions.
I've had cause to change some permissions at the top of some of these very large filesystems. By large, I mean larger than the big FacShare volume at WWU in terms of file-counts. As this is on a Windows NTFS volume, it has to walk the entire file-system to update permissions changes at the top.
This isn't the exact problem I'm fixing, but it's much like in some companies where granting permissions to specific users is done instead of to groups, and then that one user goes elsewhere and suddenly all the rights are broken and it takes a day and half to get the rights update processed (and heaven help you if it stops half-way for some reason).
Big file-systems take a long time to update rights inheritance. This has been a fact of life on Windows since the NT days. Nothing new here.
But... it doesn't have to be this way. I explain under the cut.
Continue reading An older problem.