This concept has confused me for years, but I'm beginning to get caught-up on enough of the nuance to hold opinions on it that I'm willing to defend.
This is why I have a blog.
What is immutable infrastructure?
This is a movement of systems design that holds to a few principles:
- You shouldn't have SSH/Ansible enabled on your machines.
- Once a box/image/instance is deployed, you don't touch it again until it dies.
- Yes, even for troubleshooting purposes.
Pretty simple on the face of it. Don't like how an instance is behaving? Build a new one and replace the bad instance. QED.
Refining the definition
The yes, even for troubleshooting purposes concept encodes another concept rolling through the industry right now: observability.
You can't do true immutable infrastructure until after you've already gotten robust observability tools in place. Otherwise, the SSHing and monkey-patching will still be happening.
So, Immutable Infrastructure and Observability. That makes a bit more sense to this old-timer.
Example systems
There are two design-patterns that structurally force you into taking observability principles into account, due to how they're built:
- Kubernetes/Docker-anything
- Serverless
Both of these make traditional log-file management somewhat more complex, so if engineering wants their Kibana interface into system telemetry, they're going to have to come up with ways to get that telemetry off of the logic and into the central-place using something other than log-files. Telemetry is the first step towards observability, and one most companies do instinctively.
Additionally, the (theoretically) rapid iterability of containers/functions mean much less temptation to monkey-patch. Slow iteration means more incentive to SSH or monkey-patch because that's faster than waiting for an AMI or template-image to bake.
The concept so many seem to miss
This is pretty simple.
Immutable infrastructure only applies to the pieces of your infrastructure that hold no state.
And its corollary:
If you want immutable infrastructure, you have to design your logic layers to not assume local state for any reason.
Which is to say, immutable infrastructure needs to be a DevOps thing, not just an Ops thing. Dev needs to care about it as well. If that means in-progress file-transforms get saved to a memcache/gluster/redis cluster instead of the local filesystem, so be it.
This also means that you will have both immutable and bastion infrastructures in the same overall system. Immutable for your logic, bastion for your databases and data-stores. Serverless for your NodeJS code, maintenance-windows and patching-cycles for your Postgress clusters. Applying immutable patterns to components that take literal hours to recover/re-replicate introduces risk in ways that treating them for what they are, mutable, would not.
Yeahbut, public cloud! I don't run any instances!
So, you've gone full Serverless, and all of your state is sitting in something like AWS RDS, ElasticCache, and DynamoDB, and using Workspaces for your 'inside' operations. No SSHing, to be sure. That said, this is about as automated as you can get. Even so, there are still some state operations you are subject to:
- RDS DB failovers still yield several to many seconds of "The database told me to bugger off" errors.
- RDS DB version upgrades still require a carefully choreographed dance to ensure your site continues to function, if glitchy in short periods.
- ElasticCache failovers still cause extensive latency as your underlying SDKs catch up to the new read/write replica location.
You're still not purely immutable, but you're as close as you can get in this modern age. Be proud.
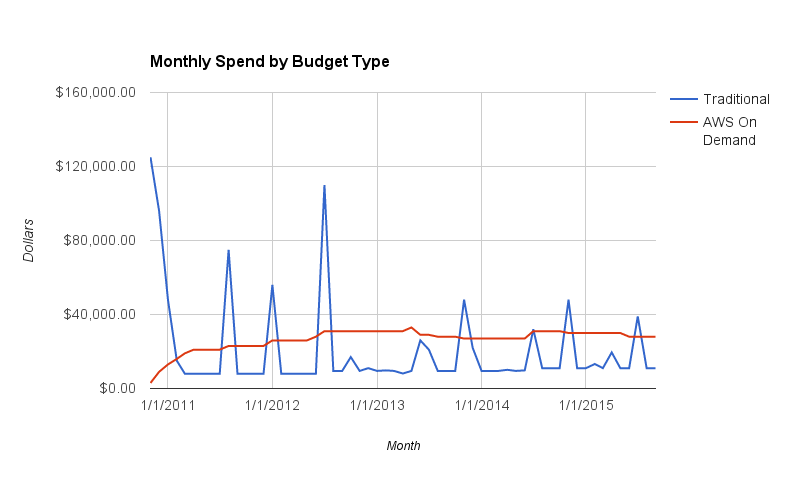 The AWS line actually results in more money over time, as AWS does a good job of capturing costs that the traditional method generally ignores or assumes is lost in general overhead. But the screaming doesn't happen at the end of four years when they run the numbers, it happens in month four when the ongoing operational spend after build-out is done is w-a-y over what it used to be.
The AWS line actually results in more money over time, as AWS does a good job of capturing costs that the traditional method generally ignores or assumes is lost in general overhead. But the screaming doesn't happen at the end of four years when they run the numbers, it happens in month four when the ongoing operational spend after build-out is done is w-a-y over what it used to be.