In most of the rest of the US June is actually a summer month, but not here in the Pacific Northwest. For us, Summer typically starts on July 12th, give or take a day. I typically make it longer for me by visiting the warmer parts of the country over the 4th of July weekend. But this June has been unusually gloomy and chilly. Take a look at the monthly temp chart from the Seattle airport. We're usually 1-5 degrees (F) colder than Seattle depending on a variety of things but the trend is still the same
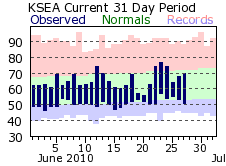
The green band represents the normal high and low. As you can see, this time of year our highs should be in the 70's, but instead they've hung in the 60's. We had a nice patch late last week, but overall the month has been markedly colder than normal. You can see where we set a record low high-temp back on the 19th.
Even during normal years we only have three months with an expected high above 70 (very roughly, June 15 through September 15). What this means is that we're actually a pretty good candidate for ambient-air datacenter cooling. Those kinds of systems didn't really exist in any meaningful way back when this building was built, but if we were to build this building again something like that would be considered.
Universities in general have an environmentalist bent to them, and WWU is not immune. We have the Huxley College of the Environment, one of the first such programs in existence. The last few buildings we've built on campus have been LEED certified to various degrees. With that kind of track-record, an ambient air system for a new large data-center is something of a gimmie.
Heck, I would not be surprised if a Capital Request gets put in sometime in the 5-10 year range to try and convert our current system to at least be partially ambient. We're running up against a power and cooling wall right now. Virtualization has helped with that quite a bit, but our UPS has been running in the 70-85% range for several years now. We're going to have to address that at some point. Since that'll also require shutting the room down for a while (eeeeek!) may as well redo cooling while they've got the availability.
We'll see if that actually happens.
The green band represents the normal high and low. As you can see, this time of year our highs should be in the 70's, but instead they've hung in the 60's. We had a nice patch late last week, but overall the month has been markedly colder than normal. You can see where we set a record low high-temp back on the 19th.
Even during normal years we only have three months with an expected high above 70 (very roughly, June 15 through September 15). What this means is that we're actually a pretty good candidate for ambient-air datacenter cooling. Those kinds of systems didn't really exist in any meaningful way back when this building was built, but if we were to build this building again something like that would be considered.
Universities in general have an environmentalist bent to them, and WWU is not immune. We have the Huxley College of the Environment, one of the first such programs in existence. The last few buildings we've built on campus have been LEED certified to various degrees. With that kind of track-record, an ambient air system for a new large data-center is something of a gimmie.
Heck, I would not be surprised if a Capital Request gets put in sometime in the 5-10 year range to try and convert our current system to at least be partially ambient. We're running up against a power and cooling wall right now. Virtualization has helped with that quite a bit, but our UPS has been running in the 70-85% range for several years now. We're going to have to address that at some point. Since that'll also require shutting the room down for a while (eeeeek!) may as well redo cooling while they've got the availability.
We'll see if that actually happens.