For a few years I've been giving talks on monitoring, observability, and how to get both. In those talks I have a Venn Diagram like this one from last year:
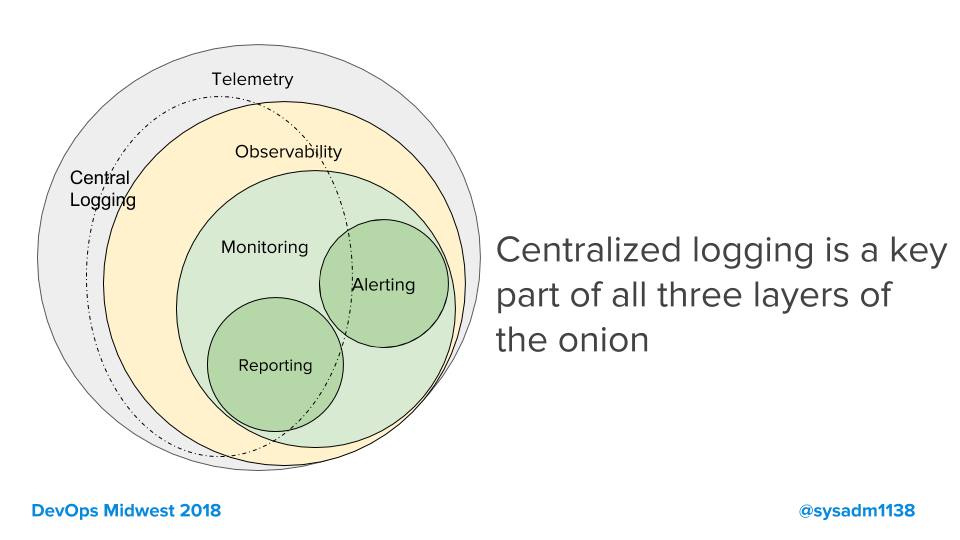
Note the outer circle, telemetry. I was using this term to capture the concept of all the debug and log-line outputs from an in-house developed piece of software. Some developer put every log-line in there for a reason. It made sense to call this telemetry. Using this concept I point out a few things:
- Telemetry is your biggest pot of data. It is the full, unredacted sequence of events.
- So big, that you probably only keep it searchable for a short period of time.
- But long enough you can troubleshoot with it and see how error rates change across releases.
- Observability is a restricted and sampled set of telemetry, kept for longer because its higher correlation.
- Higher correlation and longer time-frames make for a successful observability system.
- Monitoring is a subset of them all, since those are driving metrics, dashboard, and alarms. A highly specialized use.
A neat model, I thought. I've been using it internally for a while now, and thought it was getting traction.
Then the two major distributed tracing frameworks decided to merge and brand themselves as Open Telemetry. I understand that using Open Tracing or Distributed Tracing were non-viable; one of the two frameworks was already called Open Tracing, and Distributed Tracing is a technique not a trademark-able project name.
There is a reason I didn't call it Centralized Logging, because telemetry encompassed more than just centrallized logging. It included things that aren't centralizable because they exist in SaaS platforms that don't have log-export. Yes, I'm miffed at having to come up with a new term for this. Not sure what it will be yet.