Charity Majors had a twitter thread last night that touched on something I've kind of known for a while.
but: there are not "three pillars" of observabiity. there is only one data structure that underpins observability: the arbitrarily-wide structured data blob. consider:
-- Charity Majors (@mipsytipsy) February 22, 2019
* metrics are trivially derived from it
* logs are a sloppy version of it
* traces are a visualization of it
This goes into Observability, but touches on something I've been arguing about for some time. Specifically, the intersection of observability, monitoring, and centralized logging. Log-processing engines like Logstash are in effect Extract/Transform/Load pipelines specialized in turning arbitrary inputs into JSON blobs (or some other field-enriched data format). This observation about the core datastructure of it all has been known for a while; the phrase structured logging is what we called it.
In my talk at DevOps Midwest last year in St. Louis, one of my slides was this one.
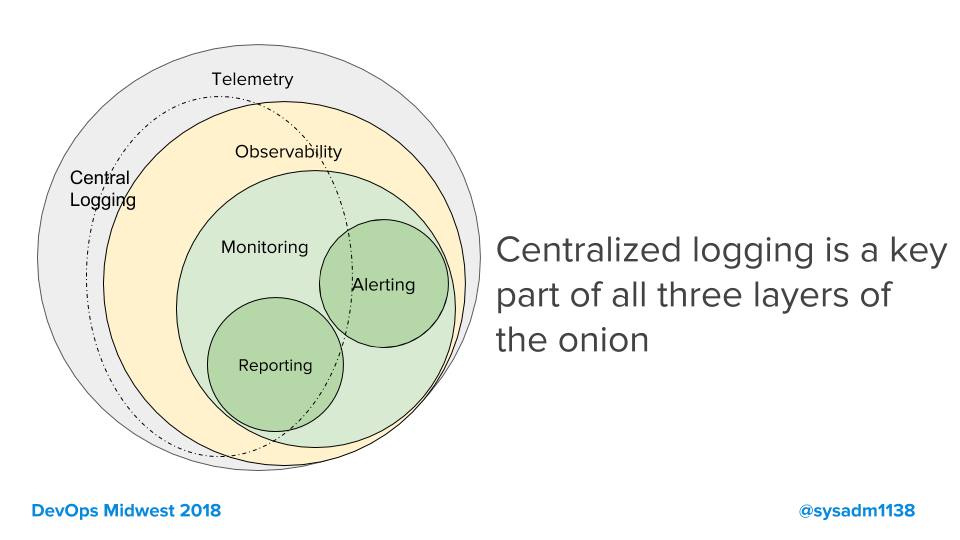
In many infrastructures, it is the centralized logging system that provides the raw data for observability.
- Centralized logging provides telemetry.
- Telemetry is needed by engineering to figure out why a specific thing went wrong at a specific point of time (traces).
- This is kept for the shorted period of time of everything because it is so huge.
- Observabilityis derived from telemetry, providing general information about how the system behaves.
- This needs to have very long time ranges in it in order to be useful, so it is a summary of the larger dataset.
- Monitoring is derived from telemetry, providing time-series datasets.
- Reporting and alertingare derived from monitoring.
- Retention of reports is determined by SLA, contract-law, and regulation.
I'm including pure polling frameworks like Nagios or SolarWinds in telemetry here, but Charity's point can be seen in that chart.
To better show what I'm talking about, take the following bit of code.
syslog.log("Entering ResizeImage. Have #{imgFormat} of #{imgSize}")
[more code]
syslog.log("Left ResizeImage. Did #{imgSize} in #{runtime} seconds.")
This is what Charity was talking about when she said logs are a sloppy version of it. You can get metrics out of this, but you have to regex the strings to pull out the numbers, which means understanding the grammar. You can get observability out of this, since the time difference between the two events tells you a lot about ResizeImage, the syslog metadata will give you some idea as to the atomicity of what happened, and the imgSize can be used to break ties. This is the kind of observability nearly all developers put into their code because outputting strings is built into everything.
The un-sloppy version of this is something like the Open Tracing framework. Using that framework, those log-injections, which still have use, would be matched with another function-call to open/close 'spans', and have any context attached to them that the software engineers think might possibly be useful someday. This is a specialized application of centralized logging, but one with the objective of making distributed systems traceable. This feed of events would be samples and uploaded to systems like Honeycomb.io for dissection and display.
Democratizing Observability
That's pretty abstract so far, but how do you actually get there?
This is where we run into some problems in the industry, since getting to this ideal of managing data with huge cardinalities doesn't currently have any obvious OSS projects.
- Small companies can get away with tools like ElasticSearch or MongoDB, because they're not big enough to hit the scaling problems with those.
- Small companies can use SaaS products like Honeycomb because their data volumes are low enough to be affordable.
- Large companies can use their ETL engineers to refine their pipelines to send statistically valid samples to SaaS products to keep them affordable.
- Very large companies can build their own high-cardinality systems.
Note the lack of mid-sized companies in that list. Too much data to afford a SaaS product, too high cardinality to use ElasticSearch, but not enough in-house resources to build their own. Another Charity tweet:
you can *approximate* a sloppy-ass version of observability using metrics, logs and traces. but you will spend an assload storing your data three different ways.
-- Charity Majors (@mipsytipsy) February 22, 2019
or you can just store it in arbitrarily-wide structured data blobs at the origin, and store it once. ob$ervability.
That assload of data comes from the operational reality of scaling up your one-datastore small-company system into a many-datastore mid-sized company system. Many datastores because each is specialized for the use-case given to it. ElasticSearch for your telemetry. OpenTSDB for your metrics. A fist-full of Python scripts and RedShift for your observability. There simply isn't much out there right now that is both battle-proven and able to deal with very high cardinalities.
So, don't feel like a looser because you've got three lakes of data. Remember, you still need telemetry even when you have an Observability system. Reducing your lakes of data from three (telemetry, metrics, observability) to two (telemetry, observability) will save you money.