There is a certain question that has shown up in pretty much every class about how to set up an X500-compliant directory service (thats things like Active Directory, NDS, and eDirectory). It goes like this:
You have been hired as a consultant to set up $FakeCorpName's new $Directory. They have major offices in five places. New York, Los Angeles, London, Sydney, and Tokyo. They have five $OldTech. What is the directory layout you recommend?
I originally ran into this particular question when I was getting my Certified Novell Administrator certification back in 1996. In that case $Directory was NDS and $OldTech was actually other NDS trees. In 2000/2001 when I was getting my Active Directory training, $Directory was AD and $OldTech was NT4 domains. The names of the countries did not vary much between the two. NYC and LA are always there, as are London and Tokyo. Sometimes Paris is there instead of Sydney. Once in a great while you'll see Hong Kong instead of Tokyo. In a fit of continental inclusiveness, I think I saw "Johannesburg" in there once (in an Exchange class IIRC). I ran into this question again recently in relation to AD.
This is a good academic question, but you will never, ever get it that easy in real life. This question is good for considering how geographically diverse corporate structure impacts your network layout and the knock-on effects that can have on your directory structure. However, the network is only a small part of the overall decision making process when it comes to problems like these.
The major part? Politics.
It is now 2010. Multi-national companies have figured out this 'office networking' thingy and have a pre-existing infrastructure. They have some kind of directory tree, somewhere, even if it only exists in their ERP system (which they all have now). They have office IT people who have been doing that work for 15+ years. A company that size has probably
eaten bought out competitors, which introduces strange networking designs to their network. Figuring out how to glue together 5 geographically separate WinNT4.0 domains
in 2010 is not useful. The problem is not technical, it's business.
1996In 1996, WAN links were expensive and slow. NDS was the only directory of note on the market (NIS+ was a unix directory, therefore completely ignored in the normal business windows-only workplace). Access across WAN links was generally discouraged unless specifically needed. Because of this, your WAN links gave you the no-brainer divisions in your NDS tree where Replicas needed to be declared. All the replication traffic would stay within that site and only external reference resolution would cross the expensive WAN. Resources the entire company needed access to might go in a specific, smaller, replica that gets put on multiple sites.
This in turn meant that the top levels of your NDS tree had a kind of default structure. Many early NDS diagrams had a structure like this:
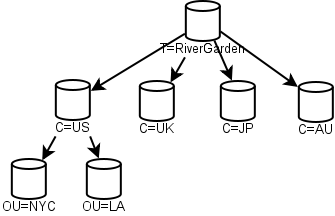
Each of the top-level "C" containers was a replica. The US example was given to show how internal organization could happen. Snazzy! However, this flew in the face of real-work experience. Companies merge. Bits get sold off. By 2000 Novell was publishing diagrams similar to this one:
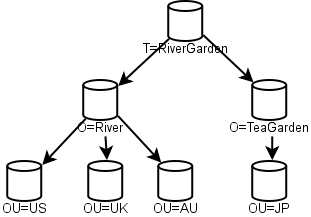
This one was designed to show how company mergers work. Gone are the early "C" containers, in their place are "O". Merging companies? Just merge that NDS tree into a new O, and tada! Then you can re-arrange your OUs and replicas at your leisure.
This was a sign that Novell, the early pioneer in directories like this, had their theory run smack into reality with bad results. The original tree style with the top level C containers didn't handle mergers and acquisitions well. Gone was the network purity of the early 1996 diagrams, now the diagrams showed some signs of political influence.
2000In 2000, Microsoft released Windows 2000 and Active Directory. The business world had been on the Internet for some time, and the .com boom was in full swing. WAN links were still expensive and slow, but not nearly as slow as they used to be. The network problem Microsoft was faced with was merging multiple NT4 domains into a single Active Directory structure.
In 2000, AD inter-DC replication was a lot noisier than eDirectory was doing at the time, so replication traffic was a major concern. This is why AD introduced the concept of Sites and inter-Site replication scheduling. Even so, the diagrams you saw then were reminiscent of the 1996 NDS diagrams:
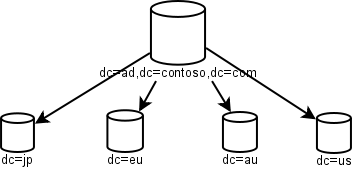
As you can see, separate domains for NYC and LA are gone, which is recognition that in-country WAN links may be fast enough for replication, but transcontinental links were still slow. Microsoft handled the mergers-and-acquisitions problem with inter-domain trusts (which, thanks to politics, tend to be hard to get rid of once in place).
AD replication improved with both Server 2003 and Server 2008. The Microsoft ecosystem got used to M&A activity the same way Novell did a decade earlier and changes were made to best practices. Also, network speeds improved a lot.
2010In 2010 WAN links are still slow relative to LAN links, but they're now fast enough that directory replication traffic is not a significant load for all but the slowest of such links. Even trans-continental WAN links are fat enough that directory replication traffic doesn't eat too much valuable resources.
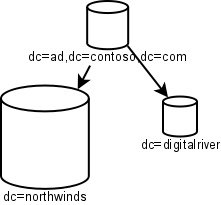
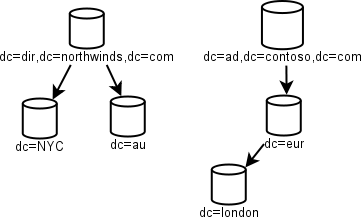
Note how simple this is.There is an empty root to act as nothing but the root of an entire tree. Northwinds is the major company and it recently bought DigitalRiver, but hasn't fully digested it yet. Note the lack of geographic separation in this chart. WAN speeds have improved (and AD replication has improved) enough that replicating even large domains over the WAN is no longer a major no-no.
And yet... you'll rarely see trees like that. That's because, as I said, network considerations are not the major driver behind organization these days, it's politics.
Take the original question at the top of this post. Consider it 5 one-domain AD trees, and each country/city is its own business unit that's large enough to have their own full IT stack (people dedicated to server, desktop, web support, and developers supporting it all), and has also been that way for a number of years. This is what you'll run into in real life. This is what will monkey-wrench the network purity of the above charts.
The biggest influence towards whether or not a one-domain solution can be reached will be the political power behind the centralizing push, and how uncowed they get when Very Important People start throwing their weight around. If the CEO is the one pushing this and brooks no argument, then, well, it's more likely to happen. If the COO is the one pushing it, but caves to pressure in order to not expend political capital with regards to unrelated projects, you may end up with a much more fragmented picture.
There will be at least one, and perhaps as many as five, business units that will insist, adamantly, that they absolutely have to keep doing things the way they've always been doing it, and they can't have other admins stomping around their walled garden in jack-boots. Whether or not they get their way is a
business decision, not a technical one. Caving into these demands will give you an AD structure that includes multiple domains, or worse, multiple forests.
In my experience, the biggest bone of contention will be who gets to be in the Domain and Enterprise Admins groups. Those groups are the God Groups for AD, and
everyone has to trust them. Demonstrating that only a few tasks require Domain Admin rights and that nearly all day-to-day administration can be done through effectively delegated rights will go a long way towards alleviating this pressure, but that may not be enough to convince business managers weighing in on the process.
The reason for this resistance is that this kind of structural change will require changes to operational procedures. You may think IT types are used to change, but you'd be wrong. Change can be resented just as fiercely in the ranks of IT-middle-managers as it is in rank-n-file clerks. Change for change's sake is doubly resented.
Overcoming this kind of political obstructionism is damned hard. It takes real people skills and political backing. This is not the kind of thing you can really teach in an MCSE/MCITP class track. Political backing has to already be in place before the project even gets off the ground.
I haven't been in an MCSE/MCITP class, so I don't know what Microsoft is teaching these days. I ran into this question in what looks like a University environment, which is a bit less up-to-date than getting it direct from Microsoft would be. Perhaps MS is teaching this with the political caveats attached. I don't know. But they should be doing so.
