I've seen this dyamic happen a couple of times now. It goes kind of like this.
October: We're going all in on AWS! It's the future. Embrace it.
November: IT is working very hard on moving us there, thank you for your patience.
December: We're in! Enjoy the future.
January: This AWS bill is intolerable. Turn off everything we don't need.
February: Stop migrating things to AWS, we'll keep these specific systems on-prem for now.
March: Move these systems out of AWS.
April: Nothing gets moved to AWS unless it produces more revenue than it costs to run.
What's prompting this is a shock that is entirely predictable, but manages to penetrate the reality distortion field of upper management because the shock is to the pocketbook. They notice that kind of thing. To illustrate what I'm talking about, here is a made-up graph showing technology spend over a course of several years.
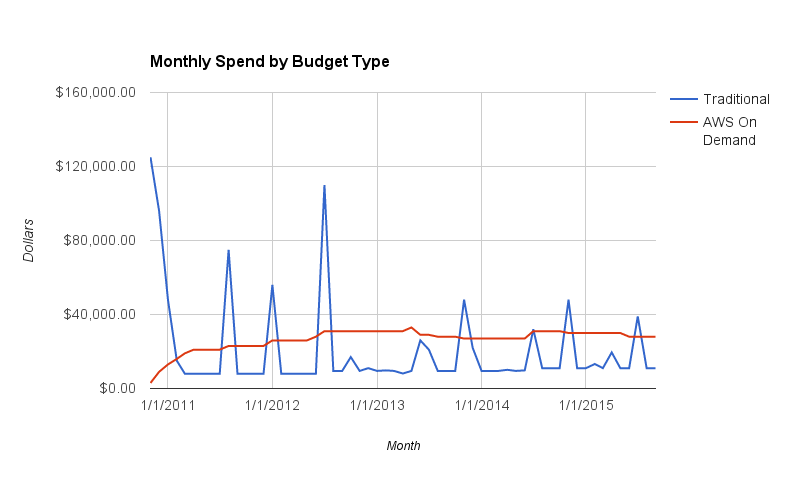 The AWS line actually results in more money over time, as AWS does a good job of capturing costs that the traditional method generally ignores or assumes is lost in general overhead. But the screaming doesn't happen at the end of four years when they run the numbers, it happens in month four when the ongoing operational spend after build-out is done is w-a-y over what it used to be.
The AWS line actually results in more money over time, as AWS does a good job of capturing costs that the traditional method generally ignores or assumes is lost in general overhead. But the screaming doesn't happen at the end of four years when they run the numbers, it happens in month four when the ongoing operational spend after build-out is done is w-a-y over what it used to be.
The spikes for traditional on-prem work are for forklifts of machinery showing up. Money is spent, new things show up, and they impact the monthly spend only infrequently. In this case, the base-charge increased only twice over the time-span. Some of those spikes are for things like maintenance-contract renewals, which don't impact base-spend one whit.
The AWS line is much less spikey, as new capabilities are assumed into the base-budget in an ongoing basis. You're no longer dropping $125K in a single go, you're dribbling it out over the course of a year or more. AWS price-drops mean that monthly spend actually goes down a few times.
Pay only for what you use!
Amazon is great at pointing that out, and hilighting the convenience of it. But what they don't mention is that by doing so, you will learn the hard way about what it is you really use. The AWS Calculator is an awesome tool, but if you don't know how your current environment works, it's like throwing darts at a wall for accurately predicting what you'll end up spending. You end up obsessing over small line-item charges you've never had to worry about before (how many IOPs do we do? Crap! I don't know! How many thousands will that cost us?), and missing the big items that nail you (Whoa! They meter bandwidth between AZs? Maybe we shouldn't be running our Hadoop cluster in multi-AZ mode).
There is a reason that third party AWS integrators are a thriving market.
Also, this 'what you use' is not subject to Oops exceptions without a lot of wrangling with Account Management. Have something that downloaded the entire EPEL repo twice a day for a month, and only learned about it when your bandwidth charge was 9x what it should be? Too bad, pay up or we'll turn the account off.
Unlike the forklift model, you pay for it every month without fail. If you have a bad quarter, you can't just not pay the bill for a few months and tru-up later. You're spending it, or they're turning your account off. This takes away some of the cost-shifting flexibility the old style had.
Unlike the forklift model, AWS prices its stuff assuming a three year turnover rate. Many companies have a 5 to 7 years lifetime for IT assets. Three to four years in production, with an afterlife of two to five years in various pre-prod, mirror, staging, and development roles.The cost of those assets therefore amortizes over 5-9 years, not 3.
Predictable spending, at last.
Hah.
Yes, it is predictable over time given accurate understanding of what is under management. But when your initial predictions end up being wildly off, it seems like it isn't predictable. It seems like you're being held over the coals.
And when you get a new system into AWS and the cost forecast is wildly off, it doesn't seem predictable.
And when your system gets the rocket-launch you've been craving and you're scaling like mad; but the scale-costs don't match your cost forecast, it doesn't seem predictable.
It's only predictable if you fully understand the cost items and how your systems interact with it.
Reserved instances will save you money
Yes! They will! Quite a lot of it, in fact. They let a company go back to the forklift-method of cost-accounting, at least for part of it. I need 100 m3.large instances, on a three year up-front model. OK! Monthly charges drop drastically, and the monthly spend chart begins to look like the old model again.
Except.
Reserved instances cost a lot of money up front. That's the point, that's the trade-off for getting a cheaper annual spend. But many companies get into AWS because they see it as cheaper than on-prem. Which means they're sensitive to one-month cost-spikes, which in turn means buying reserved instances doesn't happen and they stay on the high cost on-demand model.
AWS is Elastic!
Elastic in that you can scale up and down at will, without week/month long billing, delivery and integration cycles.
Elastic in that you have choice in your cost accounting methods. On-demand, and various kinds of reserved instances.
It is not elastic in when the bill is due.
It is not elastic with individual asset pricing, no matter how special you are as a company.
All of these things trip up upper, non-technical management. I've seen it happen three times now, and I'm sure I'll see it again at some point.
Maybe this will help you in illuminating the issues with your own management.