Having seen this failure mode happen a couple times now, it's time to share. Yes, Virgil, multi-disk failures DO happen during RAID rebuilds. I have pictures, so it MUST be true!
First, let's take a group of disks.
On this array we have defined several Volumes.
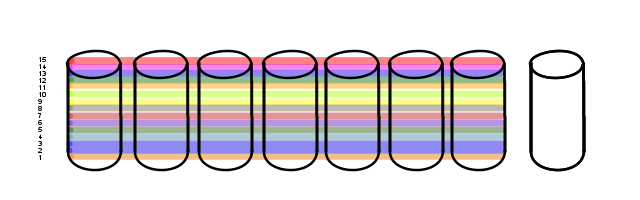
15 of them, in fact. One of which is two volumes merged together at the OS level (vols 2 & 3). That happens.
It just so happens that the particular use-case for this array is somewhat sequential. Most of the data stored on this bad boy is actually archival. The vasty majority of I/O is performed against the newest volume, with the older ones just sitting there for reference. Right now, with Vol 15 being the newest, Vol 1 hasn't had anything done to it in a couple of years.
That said, time is not kind to hard-drives.
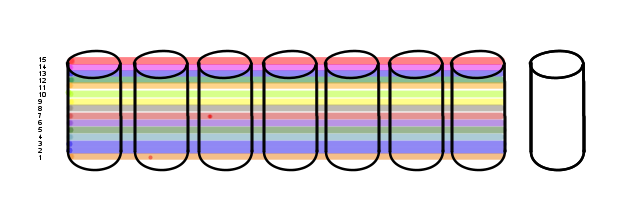
Bad blocks. Two of them. However, as the blocks aren't anywhere near the active volumes they go largely undetected.
For this scenario I'm assuming the RAID card has a failure-threshold beyond which it'll fail a drive. If it has a background scan process, as some do, it'll trip over these two blocks every few weeks. Without user-generated I/O these bad spots won't get run into often enough to fail the drives until well after the blocks went bad.
But, that doesn't happen yet.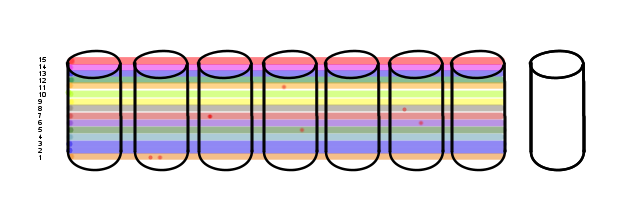
Unfortunately, there still aren't enough of 'em on a single drive to cross the failure threshold.
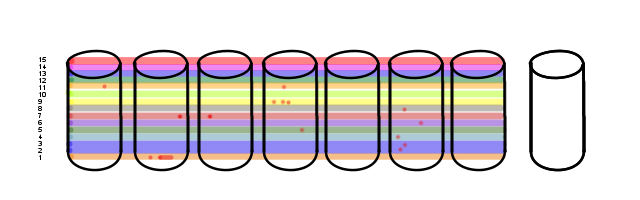
Fate is not so kind.
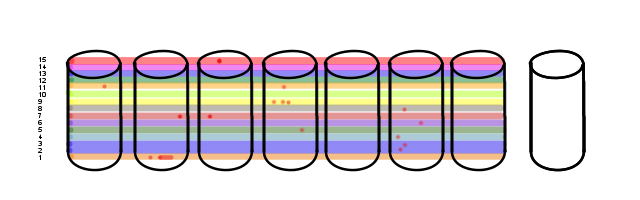
Bad block in Vol 15, the active one. This... this gets noticed. As User I/O crosses the bad block the RAID card responds with the parity-calculated block instead of the direct-read block and increments the failure count. This crosses the failure threshold really quickly.
Only, it's disk 3 that gets marked bad, not disk 2.
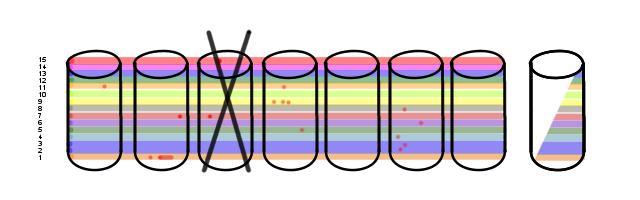
At this point a couple of things can happen.
Option 1:
The RAID card copies all the blocks off of Disk 2 onto Disk 8, and only calculates the parity information for the blocks that read bad. Of which there are but two. One of the bad blocks is in a volume with other bad blocks, but happily the bad blocks don't overlap so Disk 8 rebuilds just fine. Yay! Recovered!
We still have those other time-bombs waiting to go off, but at least the array is still running.
Option 2:
The RAID card declares Disk 2 to be FAILED and recomputes parity for the entire drive. This requires reading all 10.92TB of disk and computing the parity for it all. This is likely to take a week, and user I/O performance will most definitely be compromised during it.
The problem? Most RAID systems take the conservative route and elect to go with Option 2. If a drive is considered bad, it's considered to be ALL BAD and not to be trusted. This has complications.
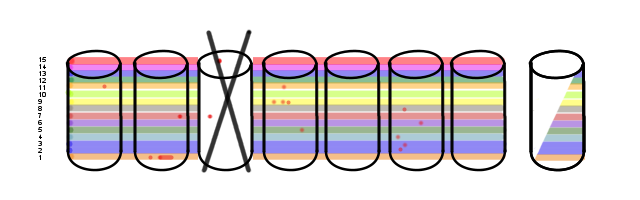
Remember Volume 1? And Disk 2? Well...
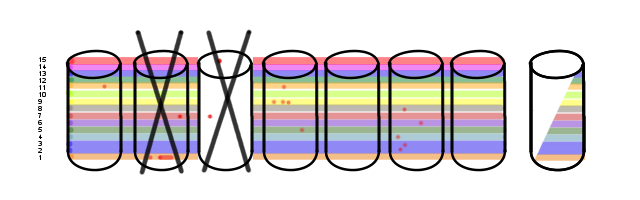
As I discussed above with Option 1, it is entirely possible to recover from this given a sufficient quantity of spare drives to rebuild onto. But it requires the right logic. Not all RAID systems have the right logic.
At this point, some RAID systems could consider this entire array to be a complete loss. Some of you may have already run into this.
Doing it smarter, some of these volumes can be recovered cleanly though still in a degraded state. All of them, in fact, as I mentioned up there with Option 1. When all is said and done, there are a bunch of drives that will have to be replaced:
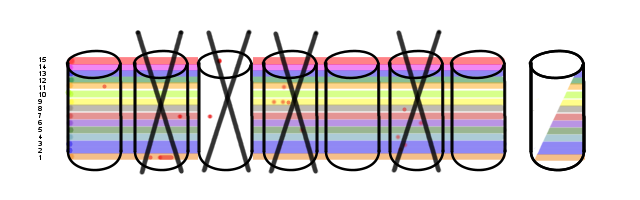
IF your RAID system is smart enough, and so long as the bad-blocks don't overlap.
If that occurs, a couple things could happen.
- The RAID card can fail the entire volume.
- The RAID card can report the block as bad to the OS.
At that point the recovery depends on the OS. Which I won't go into here.
This is but a single way this can happen. If all those volumes were regularly being read for backups, the recovery would probably have started back when there were only two bad blocks. But they weren't; they were left as long term online storage, perhaps a single backup was taken after the volume went into archive status and left alone.
But, depending on how the RAID system works just two bad blocks on separate disks can trigger an entire array failure. Or it may not notice and recover just fine, but with warnings that another disk needs to be replaced.
There are other ways a multi-disk failure can happen that I didn't cover here:
- A non-recoverable read error, a function of disk electronics not a bad block, can occur during the rebuild process. Consumer grade SATA drives are prone to this one.
- An old disk fails from over-use due to the high I/O required by the rebuild. It was going to fail anyway, but the I/O demands of the rebuild process pushed it over the edge. This is probably the most common cause of multi-disk failures and is especially bad since the entire drive disappears.
- Others I'm sure the commentariat will bring up.
Unfortunately for us all, it isn't easy to find out how a specific RAID system will react to certain edge cases like these. Yanking whole drives out gets some of it, but that doesn't handle the bad-block case I illustrated above. It's something you run into only when you've got old enough hardware that used to be good. The NRE case is better handled these days, but can still kill arrays and you can't count on older RAID systems to deal with it well.
It's for all of these reasons that you get headlines like "RAID 5 is dead" and "RAID6 isn't any better". A lot of these arguments are centered around the fact that rebuilding an array full of TB+ disks takes a really long time, and your chance of running into any of the age-based factors above is higher as a result. This is a risk that can be managed, but you do need to be aware of the risks.
Enterprise quality disks just plain last longer and are designed to run flat out for years at a time which is one way to reduce the risk. So is running smaller R5/R6 sets of disks, which reduces rebuild time. Embracing "storage is cheap" and going R1/R10 will mitigate even more since the 'array' in that case is 2 disks (or more if you're running multiple mirrors). File-systems that embrace the ideal of "disks fail, deal with it" push the problem to a higher level.
But in the end, there is a reason that disk failures tend to happen in groups!
It's worth pointing out that many hardware RAID controller support a periodic "scrubbing" operation ("Patrol Read" on Dell PERC controllers, "background scrub" on HP Smart Array controllers), and some software RAID implementations can do something similar (the "check" functionality in Linux md-style software RAID, for example). Running these kinds of tasks periodically will help maintain the "health" of your RAID arrays by forcing disks to perform block-level relocations for media defects and to accurately report uncorrectable errors up to the RAID controller or software RAID in a timely fashion.
(Zow! My OpenID is _ugly_! Evan Anderson)
Yes, that is something I should have made clearer.
This is the very reason that RAID systems have background processes that scan all the blocks. If you've ever wondered why your storage systems look like they have activity even though you know they shouldn't, this is why. To catch problems like these before they turn into multi-disk failure bombs.
I believe you mean "Disk 3" in both Option 1 and Option 2
Oh, nevermind. I see.
Re-correcting my "nevermind" -- you do mean disk 3.
I often hear that disks that were bought together and put in service at the same point in time tend to fail at similar points in time. Sounds logical to me, but you didn't mention this.
Yes, they tend to fail at the same time. Years ago a company that I worked for had a water-cooled mainframe which sprung a leak. Cost a fortune to fix. A year later the sysprogs (look it up, youngsters!) and operators were chatting and one said, 'Isn't a year since we had that leak, and isn't the other machine a year younger?'. Guess what happened the next week...