Monday, February 08, 2010
OpenSUSE Survey
http://www.surveymonkey.com/s/6MJYV7T
Thursday, December 10, 2009
Old hardware
This is one feature that Linux shares with NetWare. Because NetWare gets run on some really old crap too, since it just works, and you don't need a lot of hardware for a file-server for only 500 people. Once you get over a 1000 or very large data-sets the problem gets more interesting, but for general office-style documents... you don't need much. This is/was one of the attractions for NetWare, you need not much hardware and it runs for years.
On the factory mailing list people have been lamenting recent changes in the kernel and entire environment that has been somewhat deleterious for really old crap boxes. The debate goes back and forth, but at the end of the day the fact remains that a lot of people throw Linux on hardware they'd otherwise dispose of for being too old. And until recently, it has just worked.
However, the diaspora of hardware over the last 15 years has caught up to Linux. Supporting everything sold in the last 15 years requires a HELL of a lot of drivers. And not only that, but really old drivers need to be revised to keep up with changes in the kernel, and that requires active maintainers with that ancient hardware around for testing. These requirements mean that more and more of these really old, or moderately old but niche, drivers are drifting into abandonware-land. Linux as an ecosystem just can't keep up anymore. The Linux community decries Windows for its obsession with 'backwards compatibility' and how that stifles innovation. And yet they have a 12 year old PII box under the desk happily pushing packets.
NetWare didn't have this problem, even though it's been around longer. The driver interfaces in the NetWare kernel changed a very few times over the last 20 years (such as the DRV to HAM conversion during the NetWare 4.x era, and the introduction of SMP later on) which allowed really old drivers to continue working without revision for a really long time. This is how a 1998 vintage server could be running in 2007, and running well.
However, Linux is not NetWare. NetWare is a special purpose operating system, no matter what Novell tried in the late 90's to make it a general purpose one (NetWare + Apache + MySQL + PHP = a LAMP server that is far more vulnerable to runaway thread based DoS). Linux is a general purpose operating system. This key difference between the two means that Linux got exposed to a lot more weird hardware than NetWare ever did. SCSI attached scanners made no sense on NetWare, but they did on Linux 10 years ago. Putting any kind of high-test graphics card into a NetWare server is a complete waste, but on Linux it'll give you those awesome wibbly-windows.
There comes a time when an open source project has to cut away the old stuff. Figuring this out is hard, especially when the really old crap is running under desks or in closets entirely forgotten. It is for this reason that Smolt was born. To create a database of hardware that is running Linux, as a way to figure out driver development priorities. Both in creating new, missing drivers, and keeping up old but still frequently used drivers.
If you're running a Pentium 2-233 machine as your network's NTP server, you need to let the Linux community know about it so your platform maintains supportability. It is no longer good enough to assume that if it worked in Linux once, it'll always work in Linux.
Thursday, December 03, 2009
New linux kernels
The result is a dramatic decrease in memory usage in virtualization environments. In a virtualization server, Red Hat found that thanks to KSM, KVM can run as many as 52 Windows XP VMs with 1 GB of RAM each on a server with just 16 GB of RAM. Because KSM works transparently to userspace apps, it can be adopted very easily, and provides huge memory savings for free to current production systems. It was originally developed for use with KVM, but it can be also used with any other virtualization system - or even in non virtualization workloads, for example applications that for some reason have several processes using lots of memory that could be shared.So. Cool. And there is more:
To make easier a local configuration, a new build target has been added - make localmodconfig. It runs "lsmod" to find all the modules loaded on the current running system. It will read all the Makefiles to map which CONFIG enables a module. It will read the Kconfig files to find the dependencies and selects that may be needed to support a CONFIG. Finally, it reads the .config file and removes any module "=m" that is not needed to enable the currently loaded modules. With this tool, you can strip a distro .config of all the unuseful drivers that are not needed in our machine, and it will take much less time to build the kernel. There's an additional "make localyesconfig" target, in case you don't want to use modules and/or initrds.If you want to build a monolithic kernel for some reason, they've just made that a LOT easier. I made one a long while back in the 2.4 era and it took many tries to be sure I got the right drivers compiled in. Turn off module support and you've just made a kernel that's harder to rootkit. I don't see this improvement being as widely useful as the previous, but it is still nifty.
Labels: linux
Wednesday, December 02, 2009
OpenSUSE depreciates SaX2
There is an ongoing thread on opensuse-factory right now about the announcement to ditch SaX2 from the distro. The reason for this is pretty well laid out in the mail message. Xorg now has vastly better auto-detection capabilities, so a tool that generates a static config isn't nearly as useful as it once was. Especially if its on a laptop that can encounter any number of conference room projectors.
This is something of the ultimate fate of Xwindows on Linux. Windows has been display-plug-n-play (and working plug-n-play at that) for many, many years now. The fact that XWindows still needed a text file to work right was an anachronism. So long as it works, I'm glad to see it. As it happens, it doesn't work for me right now, but that's beside the point. Display properties, and especially display properties in an LCD world, should be plug-n-play.
As one list-member mentioned, the old way of doing it was a lot worse. What is the old way? Well... when I first started with Linux, in order to get my Xwindows working, which was the XFree86 version of Xwin by the way, I needed my monitor manual, the manual for my graphics card, a ruler, and a calculator. I kid you not. This was the only way to get truly accurate ModeLines, and it is the ModeLines that tell Xwindows what resolution, refresh rate, and bit-depth combinations it can get away with.
Early tools had databases of graphics cards and monitors that you could sort through to pick defaults. But fine tuning, or getting a resolution that the defaults didn't think was achievable, required hand hacking. In large part this was due to the analog nature of CRTs. Now that displays have all gone digital, the sheer breadth of display options is now greatly reduced (in the CRT days you really could program an 800x800x32bit display into Xwin on a regular old 4:3 monitor, and it might even have looked good. You can't do that on an LCD.).
In addition, user-space display tools in both KDE and Gnome have advanced to the point that that's what most users will ever need. While I have done the gonzo-computing of a hand-edited xwindows config file, I do not miss it. I am glad that Xwindows has gotten to this point.
Unfortunately, it seems that auto-detect on Xwindows is about as reliable as Windows ME was about that. Which is to say, most of the time. But there are enough edge cases out there where it doesn't work right to make it feel iffy. It doesn't help that people tend to run Linux on their crappiest box in the house, boxes with old CRTs that don't report their information right. So I believe SaX2 still has some life in it, until the 8 year old crap dies off in sufficient numbers that this tool that dates from that era won't be needed any more.
Wednesday, November 25, 2009
Upgrading woes
I had two problems:
- The XWindows hot-plug support for input devices just plain doesn't work on my system. This was introduced in 11.1, so that would have bit me then.
- VMWare Workstation just wouldn't compile the modules. The 11.2 kernel is too new.
I don't know why the 'evdev' stuff in xorg is failing on me. It's on my list to figure out, but as I have a working config at the moment that's kind of low priority. But that needs fixing, since 11.3 will most assuredly reintroduce that fault.
VMWare.... reportedly version 7 works without a hitch. But I can't have that yet, so I had to get 6.5 in somehow. The crowbar I mentioned was killing certain processes the vmware installer spawns to compile the kernel modules it requires. Once those were ruthelessly murdered, the installer completed and it would work. Clearly, I have to be leery of kernel updates until I can use 7.
Other than some theme tweaks that I needed to redo, this was the cleanest upgrade I've had. All the Gnome stuff worked right out of the gate, which is a first. In the past I've had to blow away most of my Gnome configs and restart from scratch. I'm glad those bugs have been ironed out.
Thursday, November 19, 2009
A disturbance in the force.
Well, it seems that the Ubuntu distribution managers agree with my friend more than the GIMP developers, as they're dropping GIMP from the default install. Why? Well...
If the most popular desktop linux on the planet calls GIMP a Photoshop replacement, then... it just might be a Photoshop replacement. No matter what the Devs think. It will be interesting to see what openSUSE and Fedora do in their next dev-cycles. If they keep GIMP, things will probably continue as usual. The same if a user revolt forces it back into the Ubuntu defaults. On the other hand, if Fedora and openSUSE follow suit, this will be a radical change in the GIMP community environment. They may start addressing the UI issues. Who knows.
- the general user doesn't use it
- its user-interface is too complex
- it's an application for professionals
- desktop users just want to edit photos and they can do that in F-Spot
- it's a photoshop replacement and photoshop isn't included by default in Windows...
- it takes up room on the disc
As it stands, Adobe has nothing to fear from GIMP. Anyone well versed in Photoshop will find the UI conventions of GIMP wildly different, and the same applies to methods to solve certain image problems(*). Adobe only needs to fear the people who a) don't want to pay the umpty hundred bucks for Photoshop, b) aren't willing to pirate a copy, and c) are willing to tough it out and learn a completely new package with radically different UI metaphors. There aren't that many of those.
Me? I've never used Photoshop. Or if I have, it was back in the early 90's. I've been using GIMP all this time and that's what I know. I intend to keep it that way since I really don't want to start paying Adobe all that money. That said, I totally understand why people don't like it. I also miss simple tools like 'draw a square', and 'draw a hollow circle'.
(*) Some of these solution paths are patented by Adobe, so no one else can do it that way if they wanted to. This is what closed source software brings you.
Tuesday, November 03, 2009
To ship or not to ship
https://features.opensuse.org/308284
If you have an opinion, go ahead and vote. Or just read the comments!
Yes, there are bugs. Perhaps a lot of them. If some of these are the type to break your install, start working on it!
Labels: linux
Thursday, October 15, 2009
Clearly I am missing something
Q: Installation from LiveDVD is broken. Bug?
A: LiveCD's are not installation sources.
Clearly, something has changed in the Land of Linux Installers. Enough mind-share has shifted to "I install my linux with my LiveDVD" that it has become a very common question on the factory list when it doesn't work. When I was a kid, we installed our linux from an Install CD. LiveCD's were for things like Knoppix, used for ass-saving or quick access to Linux tools that don't exist on Windows. I seem to remember a way to install Knoppix to a hard-drive, but I never did so.
When did this change? Is this something Ubuntu is doing?
Labels: linux
Wednesday, September 30, 2009
I have a degree in this stuff
- A career in academics
- A career in programming
Anyway. Every so often I stumble across something that causes me to go Ooo! ooo! over the sheer computer science of it. Yesterday I stumbled across Barrelfish, and this paper. If I weren't sick today I'd have finished it, but even as far as I've gotten into it I can see the implications of what they're trying to do.
The core concept behind the Barrelfish operating system is to assume that each computing core does not share memory and has access to some kind of message passing architecture. This has the side effect of having each computing core running its own kernel, which is why they're calling Barrelfish a 'multikernel operating system'. In essence, they're treating the insides of your computer like the distributed network that it is, and using already existing distributed computing methods to improve it. The type of multi-core we're doing now, SMP, ccNUMA, uses shared memory techniques rather than message passing, and it seems that this doesn't scale as far as message passing does once core counts go higher.
They go into a lot more detail in the paper about why this is. A big one is hetergenaity of CPU architectures out there in the marketplace, and they're not just talking just AMD vs Intel vs CUDA, this is also Core vs Core2 vs Nehalem. This heterogenaity in the marketplace makes it very hard for a traditional Operating System to be optimized for a specific platform.
A multikernel OS would use a discrete kernel for each microarcitecture. These kernels would communicate with each other using OS-standardized message passing protocols. On top of these microkernels would be created the abstraction called an Operating System upon which applications would run. Due to the modularity at the base of it, it would take much less effort to provide an optimized microkernel for a new microarcitecture.
The use of message passing is very interesting to me. Back in college, parallel computing was my main focus. I ended up not pursuing that area of study in large part because I was a strictly C student in math, parallel computing was a largely academic endeavor when I graduated, and you needed to be at least a B student in math to hack it in grad school. It still fired my imagination, and there was squee when the Pentium Pro was released and you could do 2 CPU multiprocessing.
In my Databases class, we were tasked with creating a database-like thingy in code and to write a paper on it. It was up to us what we did with it. Having just finished my Parallel Computing class, I decided to investigate distributed databases. So I exercised the PVM extensions we had on our compilers thanks to that class. I then used the six Unix machines I had access to at the time to create a 6-node distributed database. I used statically defined tables and queries since I didn't have time to build a table parser or query processor and needed to get it working so I could do some tests on how optimization of table positioning impacted performance.
Looking back on it 14 years later (eek) I can see some serious faults about my implementation. But then, I've spent the last... 12 years working with a distributed database in the form of Novell's NDS and later eDirectory. At the time I was doing this project, Novell was actively developing the first version of NDS. They had some problems with their implementation too.
My results were decidedly inconclusive. There was a noise factor in my data that I was not able to isolate and managed to drown out what differences there were between my optimized and non-optimized runs (in hindsight I needed larger tables by an order of magnitude or more). My analysis paper was largely an admission of failure. So when I got an A on the project I was confused enough I went to the professor and asked how this was possible. His response?
"Once I realized you got it working at all, that's when you earned the A. At that point the paper didn't matter."Dude. PVM is a message passing architecture, like most distributed systems. So yes, distributed systems are my thing. And they're talking about doing this on the motherboard! How cool is that?
Both Linux and Windows are adopting more message-passing architectures in their internal structures, as they scale better on highly parallel systems. In Linux this involved reducing the use of the Big Kernel Lock in anything possible, as invoking the BKL forces the kernel into single-threaded mode and that's not a good thing with, say, 16 cores. Windows 7 involves similar improvements. As more and more cores sneak into everyday computers, this becomes more of a problem.
An operating system working without the assumption of shared memory is a very different critter. Operating state has to be replicated to each core to facilitate correct functioning, you can't rely on a common memory address to handle this. It seems that the form of this state is key to performance, and is very sensitive to microarchitecture changes. What was good on a P4, may suck a lot on a Phenom II. The use of a per-core kernel allows the optimal structure to be used on each core, with changes replicated rather than shared which improves performance. More importantly, it'll still be performant 5 years after release assuming regular per-core kernel updates.
You'd also be able to use the 1.75GB of GDDR3 on your GeForce 295 as part of the operating system if you really wanted to! And some might.
I'd burble further, but I'm sick so not thinking straight. Definitely food for thought!
Wednesday, September 02, 2009
A clustered file-system, for windows?
http://blogs.msdn.com/clustering/archive/2009/03/02/9453288.aspx
On the surface it looks like NTFS behaving like OCFS. But Microsoft has a warning on this page:
In Windows Server® 2008 R2, the Cluster Shared Volumes feature included in failover clustering is only supported for use with the Hyper-V server role. The creation, reproduction, and storage of files on Cluster Shared Volumes that were not created for the Hyper-V role, including any user or application data stored under the ClusterStorage folder of the system drive on every node, are not supported and may result in unpredictable behavior, including data corruption or data loss on these shared volumes. Only files that are created for the Hyper-V role can be stored on Cluster Shared Volumes. An example of a file type that is created for the Hyper-V role is a Virtual Hard Disk (VHD) file.Before installing any software utility that might access files stored on Cluster Shared Volumes (for example, an antivirus or backup solution), review the documentation or check with the vendor to verify that the application or utility is compatible with Cluster Shared Volumes.So unlike OCFS2, this multi-mount NTFS is only for VM's and not for general file-serving. In theory you could use this in combination with Network Load Balancing to create a high-availability cluster with even higher uptime than failover clusters already provide. The devil is in the details though, and Microsoft aludes to them.
A file system being used for Hyper-V isn't a complex locking environment. You'll have as many locks as there are VHD files, and they won't change often. Contrast this with a file-server where you can have thousands of locks that change by the second. Additionally, unless you disable Opportunistic Locking you are at grave risk of corrupting files used by more than one user (Acess databases!) if you are using the multi-mount NTFS.
Microsoft will have to promote awareness of this type of file-system into the SMB layer before this can be used for file-sharing. SMB has its own lock layer, and this will have to coordinate the SMB layers in the other nodes for it to work right. This may never happen, we'll see.
Labels: clustering, linux, microsoft
Tuesday, September 01, 2009
Pushing a feature

With that handy "@[machinename]" in it. These days it is much less informative.

If you're using SSH X-forwarding to manage remote servers, it is entirely possible you'll have multiple YaST windows open. How can you tell them apart? Back in the 9 days it was simple, the window told you. Since 10, the marker has gone away. This hasn't changed in 11.2 either. I would like this changed so I put in a FATE request!
If you'd also like this changed, feel free to vote up feature 306852! You'll need a novell.com login to vote (the opensuse.org site uses the same auth back end so if you have one there you have one on OpenFATE).
Thank you!
Monday, August 24, 2009
Trying KDE
My first reaction? It probably matched what a lot of long-time Windows users had when they saw Vista for the first time and wanted to do something that wasn't run a web browser:
Dear God, I can't find anything, and none of my hotkeys work. THIS SUCKS!In time I calmed down. I installed gnome, and lo it was good. I also noted certain settings that I needed on the KDE side. I switched back and explored some more. Found out where they kept the hotkeys. Found out where the sub-pixel hinting settings were hiding. This made my fingers and eyeballs happier.
Now that I've tried it for a while, in fact I'm posting from it right now, it's not that bad. Another desktop-dialect I can learn. I've gotten over that initial clueless flailing and have grasped the beginnings of the basic metaphor of KDE. I still prefer the Gnome side, but we'll see where I go in the future.
Friday, August 07, 2009
Why aren't schools using open-source?
This article was primarily aimed at K-12, which is a much different environment than higher ed. For one, the budgets are a lot smaller per-pupil. However, some of the questions do apply to us as well.
As it happens, part of our mandate is to prepare our students for the Real World (tm). And until very recently, Real World meant MS Office. We've been installing Open Office along side MS Office on our lab images for some time, and according to our lab managers they've seen a significant increase on OO usage. I'm sure part of this is due to the big interface change Microsoft pushed with Office 2007, but this may also be reflective of a shift in mind-share on the part of our incoming students. Parallel installs just work, so long as you have the disk space and CPU power it is very easy to set up.
Our choice of lab OS image has many complexities, not the least of which is a lack of certain applications. There are certain applications, of which Adobe Photoshop is but one, that don't have Linux versions yet. Because of this, Windows will remain.
We could do something like allow dual-boot workstations, or have a certain percentage of each lab as Linux stations. Hard drive sizes are big enough these days that we could dual-boot like that and still allow local-partition disk-imaging, and it would allow the student a choice in environments they can work in. Now that we're moving to a Windows environment, that actually better enables interoperability (samba). Novell's NCP client for Linux was iffy performance-wise, and we had political issues surrounding CIFS usage.
However... one of the obstacles in this is the lack of Linux workstation experience on the part of our lab managers. Running lab workstations is a constant cat and mouse game between students trying to do what they want, malware attempting to sneak in, and the manager attempting to keep a clean environment. You really want your lab-manager to be good at defensive desktop management, and that skill-set is very operating system dependent. Thus the reluctance regarding wide deployment of Linux in our labs.
Each professor can help urge OSS usage by not mandating file formats for homework submissions. The University as a whole can help urge it through retraining ITS staff in linux management, not just literacy. Certain faculty can promote it in their own classes, which some already do. But then, we have the budget flexibility to dual stack if we really want to.
Tuesday, July 21, 2009
Digesting Novell financials
Yeah, well. Wrong. Novell managed to turn the corner and wean themselves off of the NetWare cash-cow. Take the last quarterly statement, which you can read in full glory here. I'm going to excerpt some bits, but it'll get long. First off, their description of their market segments. I'll try to include relevant products where I know them.
The reduction in 'services' revenue is, I believe, a reflection in a decreased willingness for companies to pay Novell for consulting services. Also, Novell has changed how they advertise their consulting services which seems to also have had an impact. That's the economy for you. The raw numbers:We are organized into four business unit segments, which are Open Platform Solutions, Identity and Security Management, Systems and Resource Management, and Workgroup. Below is a brief update on the revenue results for the second quarter and first six months of fiscal 2009 for each of our business unit segments:
•
Within our Open Platform Solutions business unit segment, Linux and open source products remain an important growth business. We are using our Open Platform Solutions business segment as a platform for acquiring new customers to which we can sell our other complementary cross-platform identity and management products and services. Revenue from our Linux Platform Products category within our Open Platform Solutions business unit segment increased 25% in the second quarter of fiscal 2009 compared to the prior year period. This product revenue increase was partially offset by lower services revenue of 11%, such that total revenue from our Open Platform Solutions business unit segment increased 18% in the second quarter of fiscal 2009 compared to the prior year period.
Revenue from our Linux Platform Products category within our Open Platform Solutions business unit segment increased 24% in the first six months of fiscal 2009 compared to the prior year period. This product revenue increase was partially offset by lower services revenue of 17%, such that total revenue from our Open Platform Solutions business unit segment increased 15% in the first six months of fiscal 2009 compared to the prior year period.
[sysadmin1138: Products include: SLES/SLED]
•
Our Identity and Security Management business unit segment offers products that we believe deliver a complete, integrated solution in the areas of security, compliance, and governance issues. Within this segment, revenue from our Identity, Access and Compliance Management products increased 2% in the second quarter of fiscal 2009 compared to the prior year period. In addition, services revenue was lower by 45%, such that total revenue from our Identity and Security Management business unit segment decreased 16% in the second quarter of fiscal 2009 compared to the prior year period.
Revenue from our Identity, Access and Compliance Management products decreased 3% in the first six months of fiscal 2009 compared to the prior year period. In addition, services revenue was lower by 40%, such that total revenue from our Identity and Security Management business unit segment decreased 18% in the first six months of fiscal 2009 compared to the prior year period.
[sysadmin1138: Products include: IDM, Sentinal, ZenNAC, ZenEndPointSecurity]
•
Our Systems and Resource Management business unit segment strategy is to provide a complete “desktop to data center” offering, with virtualization for both Linux and mixed-source environments. Systems and Resource Management product revenue decreased 2% in the second quarter of fiscal 2009 compared to the prior year period. In addition, services revenue was lower by 10%, such that total revenue from our Systems and Resource Management business unit segment decreased 3% in the second quarter of fiscal 2009 compared to the prior year period. In the second quarter of fiscal 2009, total business unit segment revenue was higher by 8%, compared to the prior year period, as a result of our acquisitions of Managed Object Solutions, Inc. (“Managed Objects”) which we acquired on November 13, 2008 and PlateSpin Ltd. (“PlateSpin”) which we acquired on March 26, 2008.
Systems and Resource Management product revenue increased 3% in the first six months of fiscal 2009 compared to the prior year period. The total product revenue increase was partially offset by lower services revenue of 14% in the first six months of fiscal 2009 compared to the prior year period. Total revenue from our Systems and Resource Management business unit segment increased 1% in the first six months of fiscal 2009 compared to the prior year period. In the first six months of fiscal 2009 total business unit segment revenue was higher by 12% compared to the prior year period as a result of our Managed Objects and PlateSpin acquisitions.
[sysadmin1138: Products include: The rest of the ZEN suite, PlateSpin]
•
Our Workgroup business unit segment is an important source of cash flow and provides us with the potential opportunity to sell additional products and services. Our revenue from Workgroup products decreased 14% in the second quarter of fiscal 2009 compared to the prior year period. In addition, services revenue was lower by 39%, such that total revenue from our Workgroup business unit segment decreased 17% in the second quarter of fiscal 2009 compared to the prior year period.
Our revenue from Workgroup products decreased 12% in the first six months of fiscal 2009 compared to the prior year period. In addition, services revenue was lower by 39%, such that total revenue from our Workgroup business unit segment decreased 15% in the first six months of fiscal 2009 compared to the prior year period.
[sysadmin1138: Products include: Open Enterprise Server, GroupWise, Novell Teaming+Conferencing,
| | | Three months ended | | |||||||||||||||||||
| | | April 30, 2009 | | | April 30, 2008 | | ||||||||||||||||
| (In thousands) | | Net revenue | | Gross profit | | | Operating income (loss) | | | Net revenue | | Gross profit | | | Operating income (loss) | | ||||||
| Open Platform Solutions | | $ | 44,112 | | $ | 34,756 | | | $ | 21,451 | | | $ | 37,516 | | $ | 26,702 | | | $ | 12,191 | |
| Identity and Security Management | | | 38,846 | | | 27,559 | | | | 18,306 | | | | 46,299 | | | 24,226 | | | | 12,920 | |
| Systems and Resource Management | | | 45,354 | | | 37,522 | | | | 26,562 | | | | 46,769 | | | 39,356 | | | | 30,503 | |
| Workgroup | | | 87,283 | | | 73,882 | | | | 65,137 | | | | 105,082 | | | 87,101 | | | | 77,849 | |
| Common unallocated operating costs | | | — | | | (3,406 | ) | | | (113,832 | ) | | | — | | | (2,186 | ) | | | (131,796 | ) |
| | | | ||||||||||||||||||||
| Total per statements of operations | | $ | 215,595 | | $ | 170,313 | | | $ | 17,624 | | | $ | 235,666 | | $ | 175,199 | | | $ | 1,667 | |
| | | | ||||||||||||||||||||
| | | Six months ended | | |||||||||||||||||||
| | | April 30, 2009 | | | April 30, 2008 | | ||||||||||||||||
| (In thousands) | | Net revenue | | Gross profit | | | Operating income (loss) | | | Net revenue | | Gross profit | | | Operating income (loss) | | ||||||
| Open Platform Solutions | | $ | 85,574 | | $ | 68,525 | | | $ | 40,921 | | | $ | 74,315 | | $ | 52,491 | | | $ | 24,059 | |
| Identity and Security Management | | | 76,832 | | | 52,951 | | | | 35,362 | | | | 93,329 | | | 52,081 | | | | 29,316 | |
| Systems and Resource Management | | | 90,757 | | | 74,789 | | | | 52,490 | | | | 90,108 | | | 74,847 | | | | 58,176 | |
| Workgroup | | | 177,303 | | | 149,093 | | | | 131,435 | | | | 208,840 | | | 173,440 | | | | 155,655 | |
| Common unallocated operating costs | | | — | | | (7,071 | ) | | | (228,940 | ) | | | — | | | (4,675 | ) | | | (257,058 | ) |
| | | | ||||||||||||||||||||
| Total per statements of operations | | $ | 430,466 | | $ | 338,287 | | | $ | 31,268 | | | $ | 466,592 | | $ | 348,184 | | | $ | 10,148 | |
So, yes. Novell is making money, even in this economy. Not lots, but at least they're in the black. Their biggest growth area is Linux, which is making up for deficits in other areas of the company. Especially the sinking 'Workgroup' area. Once upon a time, "Workgroup," constituted over 90% of Novell revenue.
Revenue from our Workgroup segment decreased in the first six months of fiscal 2009 compared to the prior year period primarily from lower combined OES and NetWare-related revenue of $13.7 million, lower services revenue of $10.5 million and lower Collaboration product revenue of $6.3 million. Invoicing for the combined OES and NetWare-related products decreased 25% in the first six months of fiscal 2009 compared to the prior year period. Product invoicing for the Workgroup segment decreased 21% in the first six months of fiscal 2009 compared to the prior year period.Which is to say, companies dropping OES/NetWare constituted the large majority of the losses in the Workgroup segment. Yet that loss was almost wholly made up by gains in other areas. So yes, Novell has turned the corner.
Another thing to note in the section about Linux:
The invoicing decrease in the first six months of 2009 reflects the results of the first quarter of fiscal 2009 when we did not sign any large deals, many of which have historically been fulfilled by SUSE Linux Enterprise Server (“SLES”) certificates delivered through Microsoft.Which is pretty clear evidence that Microsoft is driving a lot of Novell's Operating System sales these days. That's quite a reversal, and a sign that Microsoft is officially more comfortable with this Linux thing.
Labels: linux, microsoft, netware, novell, OES, sled, sles, sysadmin, zenworks
Wednesday, July 08, 2009
Google and Microsoft square off
What the new Google OS, called Chrome to make it confusing, is under the hood is Linux. They created, "a new windowing system on top of a Linux kernel." This might be a replacement for X-Windows, or it could just be a replacement for Gnome/KDE.
To my mind, this isn't the battle of the titans some think it is. Linux on the net-top has been around for some time. Long enough for a separate distribution to gain some traction (hello Moblin). What google brings to the party that moblin does not is its name. That alone will drive up adoption, regardless of how nice the user experience ends up being.
And finally, this is a distribution aimed at the cheapest (but admittedly fastest growing) segment of the PC market: sub-$500 laptops. Yes, Chrome could further chip away at the Microsoft desktop lock-in, but so far I have yet to see anything about Chrome that could actually do something significant about that. Chrome is far more likely to chip away at the Linux market-share than it is the Windows market-share, since it shares an ecosystem with Linux.
Microsoft is not quaking in its boots about this anouncement. With the release of Android, it was pretty clear that a move like this was very likely. Microsoft itself has admitted that it needs to do better in the, "slow but cheap," hardware space. They're already trying to compete in this space. Chrome will be another salvo from Google, but it won't make a hole below the water-line.
Wednesday, June 24, 2009
Why ext4 is very interesting
- Large directories. It can now handle very large directories. One source says unlimited directory sizes, and another less reliable source says sizes up to 64,000 files. This is primo for, say, a mailer. GroupWise would be able to run on this, if one was doing that.
- Extent-mapped files. More of a feature for file-systems that contain a lot of big files rather than tens of millions of 4k small files. This may be an optional feature. Even so, it replicates an XFS feature which makes ext4 a top contender for the MythTV and other linux-based PVR products. Even SD video can be 2GB/hour, HD can be a lot larger.
- Delayed allocation. Somewhat controversial, but if you have very high faith in your power environment, it can make for some nice performance gains. It allows the system to hold off on block allocation until a process either finishes writing, or triggers a dirty-cache limit, which further allows a decrease in potential file-frag and helps optimize disk I/O to some extent. Also, for highly transient files, such as mail queue files, it may allow some files to never actually hit disk between write and erase, which further increases performance. On the down side, in case of sudden power loss, delayed writes are simply lost completely.
- Persistent pre-allocation. This is a feature XFS has that allows a process to block out a defined size of disk without actually writing to it. For a PVR application, the app could pre-allocate a 1GB hunk of disk at the start of recording and be assured that it would be as contiguous as possible. Certain bittorrent clients 'preallocate' space for downloads, though some fake it by writing 4.4GB of zeros and overwriting the zeros with the true data as it comes down. This would allow such clients to truly pre-allocate space in a much more performant way.
- Online defrag. On traditional rotational media, and especially when there isn't a big chunk of storage virtualization between the server and the disk such as that provided by a modern storage array, this is much nicer. This is something else that XFS had, and ext is now picking up. Going back to the PVR again, if that recording pre-allocated 1GB of space and the recording is 2 hours long, at 2GB/hour it'll need a total of 4 GB. In theory each 1GB chunk could be on a completely diffrent part of the drive. An online defrag allows that file to be made contiguous without file-system downtime.
- SSD: A bad idea for SSD media, where you want to conserve your writes, and doesn't suffer a performance penalty for frag. Hopefully, the efstools used to make the filesystem will be smart enough to detect SSDs and set features appropriately.
- Storage Arrays: Not a good idea for extensive disk arrays like the HP EVA line. These arrays virtualize storage I/O to such an extent that file fragmentation doesn't cause the same performance problems as would a simple 6-disk RAID5 array would experience.
- Higher resolution time-stamps. This doesn't yet have much support anywhere, but it allows timestamps with nanosecond resolution. This may sound like a strange thing to put into a 'nifty features' list, but this does make me go "ooo!".
Wednesday, June 17, 2009
Editing powershell scripts in VIM
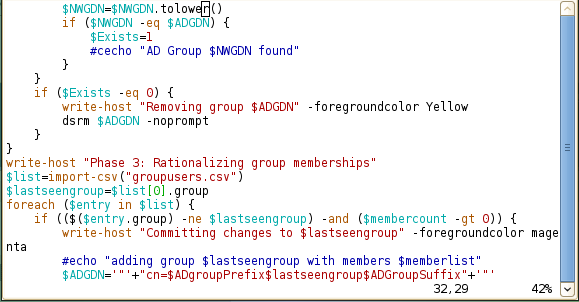
The fact that powershell scripting has gotten enough traction that someone felt the need to code up a powershell syntax file for vim is very interesting. I'm perfectly willing to reap the rewards.
Monday, June 15, 2009
openSUSE 11.2 milestone 2
See?
Also, as of milestone 2, ext4 is the default file-system.
Friday, June 12, 2009
Explaining LDAP.
"How would you explain LDAP to a sysadmin who'd've heard of it, but not interacted with it before."
My first reaction illustrates my own biases rather well. "How could they NOT have heard of it before??" goes the rant in my head. Active Directory, choice of enterprise Windows deployments everywhere, includes both X500 and LDAP. Anyone doing unified authentication on Linux servers is using either LDAP or WinBind, which also uses LDAP. It seems that any PHP application doing authentication probably has an LDAP back end to it1. So it seems somewhat disingenuous to suppose a sysadmin who didn't know what LDAP was and could do.
But then, I remind myself, I've been playing with X500 directories since 1996 so LDAP was just another view on the same problem to me. Almost as easy as breathing. This proposed sysadmin probably has been working in a smaller shop. Perhaps with a bunch of Windows machines in a Workgroup, or a pack of Linux application servers that users don't generally log in to. It IS possible to be in IT and not run into LDAP. This is what makes this particular question an interesting challenge, since I've been doing it long enough that the definition is no longer ready to my head. Unfortunately for the person I'm about to info-dump upon, I get wordy.
LDAP.... Lightweight Directory Access Protocol. It came into existence as a way to standardize TCP access to X500 directories. X500 is a model of directory service that things like Active Directory and Novell eDirectory/NDS implemented. Since X500 was designed in the 1980's it is, perhaps, unwarrantedly complex (think ISDN), and LDAP was a way to simplify some of that complexity. Hence the 'lightweight".Yeah, I get wordy.
LDAP, and X500 before it, are hierarchical in organization, but doesn't have to be. Objects in the database can be organized into a variety of containers, or just one big flat blob of objects. That's part of the flexibility of these systems. Container types vary between directory implementation, and can be an Organizational Unit (OU=), a DNS domain (DC=), or even a Cannonical Name (CN=), if not more. The name of an object is called the Distinguished Name (DN), and is composed of all the containers up to root. An example would be:
CN=Fred,OU=Users,DC=organization,DC=edu
This would be the object called Fred, in the 'Users' Organizational Unit, which is contained in the organization.edu domain.
Each directory has a list of classes and attributes allowable in the directory, and this is called a Schema. Objects have to belong to at least one class, and can belong to many. Belonging to a class grants the object the ability to define specific attributes, some of which are mandatory similar to Primary Keys in database tables.
Fred is a member of the User class, which itself inherits from the Top class. The Top class is the class that all other classes inherit from, as it defines the bare minimum attributes needed to define an object in the database. The User class can then define additional attributes that are distinct to the class, such as "first name", "password", and "groupMembership".
The LDAP protocol additionally defines a syntax for searching the directory for information. The return format is also defined. Lets look at the case of an authentication service such as a web-page or Linux login.
A user types in "fred" at the Login prompt of an SSH login to a linux server. The linux server then asks for a password, which the user provides. The Pam back-end then queries the LDAP server for objects of class User named "fred", and gets one, located at CN=Fred,OU=Users,DC=organization,DC=edu. It then queries the LDAP server for objects of class Group that are named CN=LinuxServerAccess,OU=Servers,DC=Organization,DC=EDU, and pulls the membership attributes. It finds that Fred is in this group, and therefore allowed to log in to that server. It then makes a third connection to the LDAP server and attempts to authenticate as Fred, with the password Fred supplied at the SSH login. Since Fred did not fat finger his password, the LDAP server allows the authenticated login. The Linux server detects the successfull login, and logs out of LDAP, finally permiting Fred to log in by way of SSH.
As I said before, these databases can be organized any which way. Some are organized based on the Organizational Chart of the organization, not with all the users in one big pile like the above example. In that case, Fred's distinguished-name could be as long as:
CN=Fred,ou=stuhelpdesk,ou=DesktopSupport,ou=InfoTechSvcs,ou=AcadAffairs,dc=organization,dc=edu
How to organize the directory is up to the implementers, and is not included in the standards.
The higher performing LDAP systems, such as the systems that can scale to 500,000 objects or higher, tend to index their databases in much the same way that relational databases do. This greatly speeds up common searches. Searching for an object's location is often one of the fastest searches an LDAP system can perform. Because of this LDAP very frequently is the back end for authentication systems.
LDAP is in many ways a speciallized identity database. If done right, on identical hardware it can easilly outperform even relational-databases in returning results.
Any questions?
1: Yes, this is wrong. MySQL contains a lot, if not most, of these PHP-application logins on the greater internet. I said I had my biases, right?
![]()
