We're moving our BackupExec environment to HP DataProtector. Don't ask why, it made sense at the time.
Once of the niiiice things about DP is what's called, "Enhanced Incremental Backup". This is a de-duplication strategy, that only backs up files that have changed, and
only stores the changed blocks. From these incremental backups you can construct synthetic full backups, which are just pointer databases to the blocks for that specified point-in-time. In theory, you only need to do one full backup, keep that backup forever, do enhanced incrementals, then periodically construct synthetic full backups.
We've been using it for our BlackBoard content store. That's around... 250GB of file store. Rather than keep 5 full 275GB backup files for the duration of the backup rotation, I keep 2 and construct synthetic fulls for the other 3. In theory I could just go with 1, but I'm paranoid :). This greatly reduces the amount of disk-space the backups consume.
Unfortunately, there is a problem with how DP does this. The problem rests on the client side of it. In the "$InstallDir$\OmniBack\enhincrdb" directory it constructs a file hive. An extensive file hive. In this hive it keeps track of file state data for all the files backed up on that server. This hive is constructed as follows:
- The first level is the mount point. Example: enhincrdb\F\
- The 2nd level are directories named 00-FF which contain the file state data itself
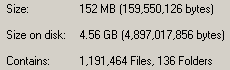
On our BlackBoard content store, it had 2.7
million files in that hive, and consumed around 10.5GB of space. We noticed this behavior when C: ran out of space. Until this happened, we've never had a problem installing backup agents to C: before. Nor did we find any warnings in the documentation that this directory could get so big.
The last real full backup I took of the content store backed up just under 1.7 million objects (objects = directory entries in NetWare, or inodes in unix-land). Yet the enhincrdb hive had 2.7 million objects. Why the difference? I'm not sure, but I suspect it was keeping state data for 1 million objects that no longer were present in the backup. I have trouble believing that we managed to churn over 60% of the objects in the store in the time I have backups, so I further suspect that it isn't cleaning out state data from files that no longer have a presence in the backup system.
DataProtector doesn't support Enhanced Incrementals for NetWare servers, only Windows and possibly Linux. Due to how this is designed, were it to support NetWare it would create
absolutely massive directory structures on my SYS: volumes. The FACSHARE volume has about 1.3TB of data in it, in about 3.3 million directory entries. The average FacStaff User volume (we have 3) has about 1.3 million, and the average Student User volume has about 2.4 million. Due to how our data works, our Student user volumes have a high churn rate due to students coming and going. If FACSHARE were to share a cluster node with one Student user volume and one FacStaff user volume, they have a combined directory-entry count of 7.0 million directory entries. This would generate, at first, a \enhincrdb directory with 7.0 million files. Given our regular churn rate, within a year it could easily be over 9.0 million.
When you move a volume to another cluster node, it will create a hive for that volume in the \enhincrdb directory tree. We're seeing this on the BlackBoard Content cluster. So given some volumes moving around, and it is quite conceivable that each cluster node will have each cluster volume represented in its own \enhincrdb directory. Which will mean over 15 million directory-entries parked there on each SYS volume, steadily increasing as time goes on taking who knows how much space.
And as anyone who has EVER had to do a consistency check of a volume that size knows (be it vrepair, chkdsk, fsck,or nss /poolrebuild), it takes a whopper of a long time when you get a lot of objects on a file-system. The old Traditional File System on NetWare could only support 16 million directory entries, and DP would push me right up to that limit. Thank heavens NSS can support w-a-y more then that. You better hope that the file-system that the \enhincrdb hive is on never has any problems.
But, Enhanced Incrementals only apply to Windows so I don't have to worry about that. However.... if they really do support Linux (and I think they do), then when I migrate the cluster to OES2 next year this could become a very real problem for me.
DataProtector's "Enhanced Incremental Backup" feature is
not designed for the size of file-store we deal with. For backing up the C: drive of application servers or the inetpub directory of IIS servers, it would be just fine. But for file-servers? Good gravy, no! Unfortunately, those are the servers
in most need of de-dup technology.