The question on my mind is why is ncp serving on OES-Linux so much more resource intensive than OES-NetWare? The answers are not immediately clear, and I lack certain developer tools to answer why that may be. So I'm left with wild speculation, which I'll indulge in.
I strongly suspect a contributing factor is where the code executes. In NetWare everything is in Ring 0 (kernel-land) unless exiled to a Protected Memory Space whereupon it executes in Ring 3 (user-land). My CNE classes said that stuff running in a protected memory space typically runs 3-5% slower than in the OS memory space on NetWare. On Linux, at least as far as the 2.6 kernels anyway, memory accessible from Ring 0 is limited to the first 1GB of RAM and most processes are supposed to run in Ring 3. This is the architecture that permits things like "kill -9 [pid]" to work on Linux, but abend the server in NetWare.
There was a very handy slide at BrainShare 2006 that showed the differences in the NCP/NSS architecture in NetWare and Linux. The session was IO104: File System Roadmap by Richard Jones. Because you can purchase your very own
BrainShare DVD, I'm going to assume that any NDAs on this information have lapsed. You'll want to open these links in different tabs, I'll be referring to the contents of them.
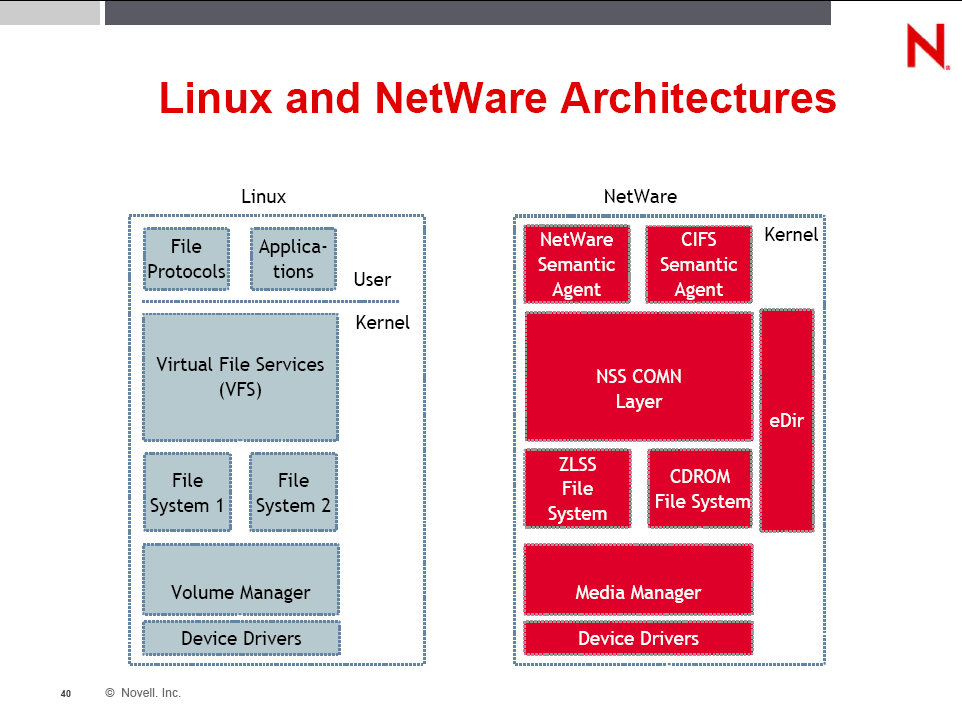
IO104 Slide 40: Linux and NetWare ArchitecturesThe NetWare architecture is very familiar. I've been looking at that chart for years. The thing to note is that the NSS and NCP bits are right next to eachother in kernel-land, so run well together with little interference.
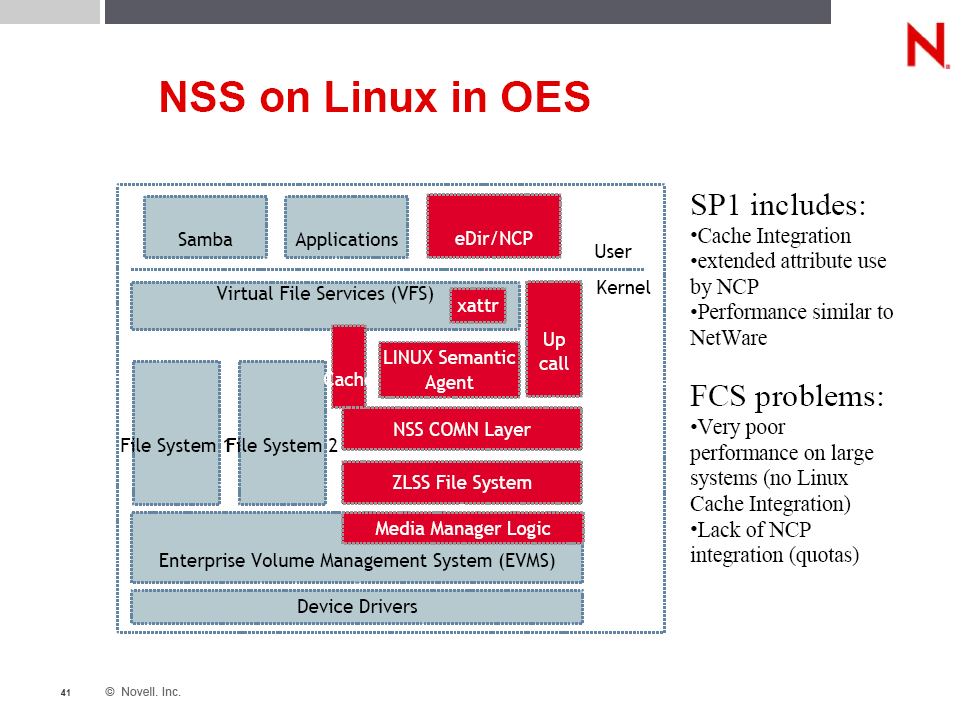
IO104 Slide 41: NSS on Linux in OESThis is how NSS and NCP are crammed into Linux. The 'up call' box is how communication between kernel-land and user-land are performed. Every piece of I/O that comes in on an NSS volume over any file protocol, NCP, Samba, NFS, or AFP, has to pass the user/kernel interface. If you look at slide 40 you can see that this is true for all file-systems on Linux.
The side information on slide 41 hints at a major problem when OES-Linux first shipped. At that time the file-cache was being kept in kernel-land like it is in NetWare. This gave some screaming numbers. Unfortunately Linux is limited to 1GB of RAM in kernel-land, and that has to be shared with everything in kernel-land. So it screamed... so long as you had very small file systems. Ahem. SP1 changed that so NSS could use Linux's native caching mechanism. It dropped the speed a bit, but it could again handle large file-systems.
Since every I/O request on a file-system has to pass the computing equivalent of the blood/brain barrier, this introduces certain lags. The true impact of this is unknown to me, as my linux-fu is too weak to know where to stick the probes to get an idea as to where all that CPU is going. Watching the split of load types I clearly saw that the CPU spent very little time in IOWAIT, and split roughly evenly between USER and SYSTEM. The NCP server was doing something, but NSS (all that SYSTEM time) clearly was quite busy as well. Due to how file-servers are handled on Linux if I had run this against Samba the busy process would have been SMBD, since CPU for file-system work is 'charged' against the calling process.
Then there is the possibility of just not having fully optimized code. I've heard that NSS as a linux file system runs 'only' 12% slower than reiser (when called locally on the Linux server, and not over a file-serving protocol), which says that NSS is pretty butch as it is. Scale is the key question, though.
The same File System Futures presentation had a few slides about where NSS is likely to go in future revisions of OES and SLES, where 'future' is likely the version past the one coming out Real Soon Now, and it looks quite promising. The block diagram for how the NetWare Services shim into Linux is much cleaner. The plan, as of March, was to shim in a 'NetWare Modular Features' layer between the file-systems and the Virtual File Services layer. The advantage to this would be at a minimum NetWare-style trustees on reiser, JFS, UFS, etc.
Once the next version of OES ships I'll see if I can get the hardware to re-run the dir-create and file-create tests. Even doing a single workstation should tell me what improvements, if any, were put into OES when it comes to scalability.
Tags: novell, oes
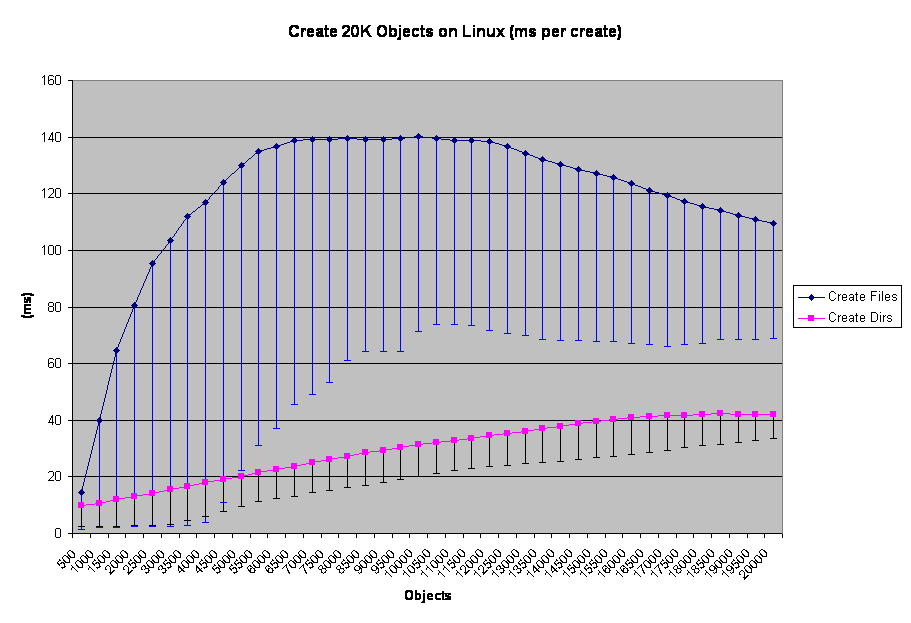 I just put the Min values in the error bars to make it a cleaner graph. But here you can see the trend mentioned in the file-create tess about the 4000 object line. Only here 4500 objects seems to be the point where file-create passes dir-create in terms of time per operation. This is a result of CPU usage and the fact that file-create appears to be more affected by it than NetWare is. The idential NetWare chart is illustrative, but since CPU never went above 70% for more than a few moments it isn't a pure apples-to-apples comparison.
I just put the Min values in the error bars to make it a cleaner graph. But here you can see the trend mentioned in the file-create tess about the 4000 object line. Only here 4500 objects seems to be the point where file-create passes dir-create in terms of time per operation. This is a result of CPU usage and the fact that file-create appears to be more affected by it than NetWare is. The idential NetWare chart is illustrative, but since CPU never went above 70% for more than a few moments it isn't a pure apples-to-apples comparison.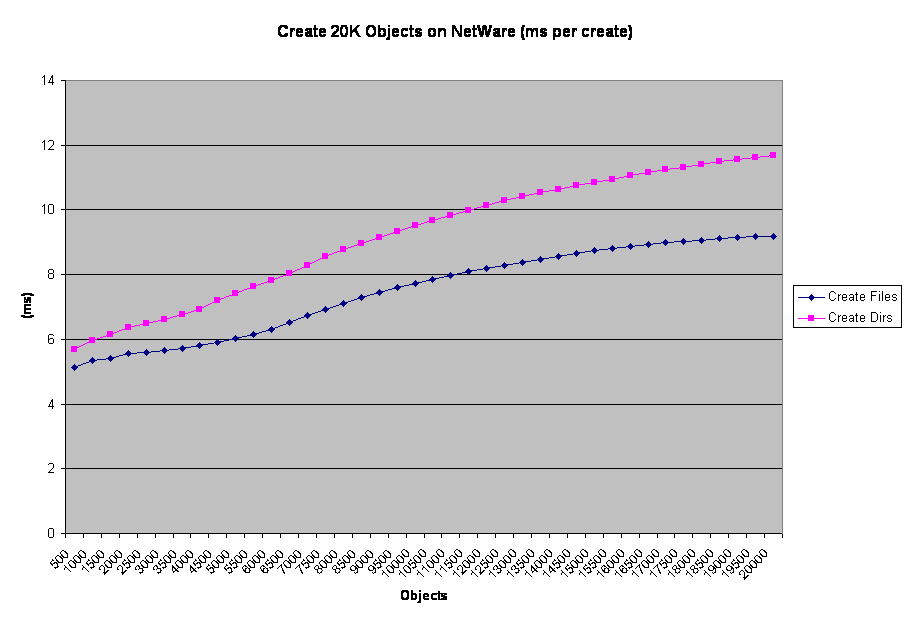 In this case, file-create remains below dir-create for the whole run. What's more, dir-create drove CPU a lot harder than file-create did. The early data in the Linux run shows that OES-Linux would follow this file-create-is-faster pattern given sufficient CPU.
In this case, file-create remains below dir-create for the whole run. What's more, dir-create drove CPU a lot harder than file-create did. The early data in the Linux run shows that OES-Linux would follow this file-create-is-faster pattern given sufficient CPU. This chart is interesting in several ways. First of all, note the lower error bars for the Linux line. Those bars overlap and up to about 4000 files actually is below the NetWare average. This says to me that when there is CPU room, Linux may be faster than NetWare when responding to file creates. This particular line was caused by the same method as the previous test, namely that some test stations started up to 30 seconds before the whole group was running and therefore had a window of uncontended I/O. Those same workstations finished their tests while others were still around 12000 files, which further explains the downward trend of the Linux line above that threshold.
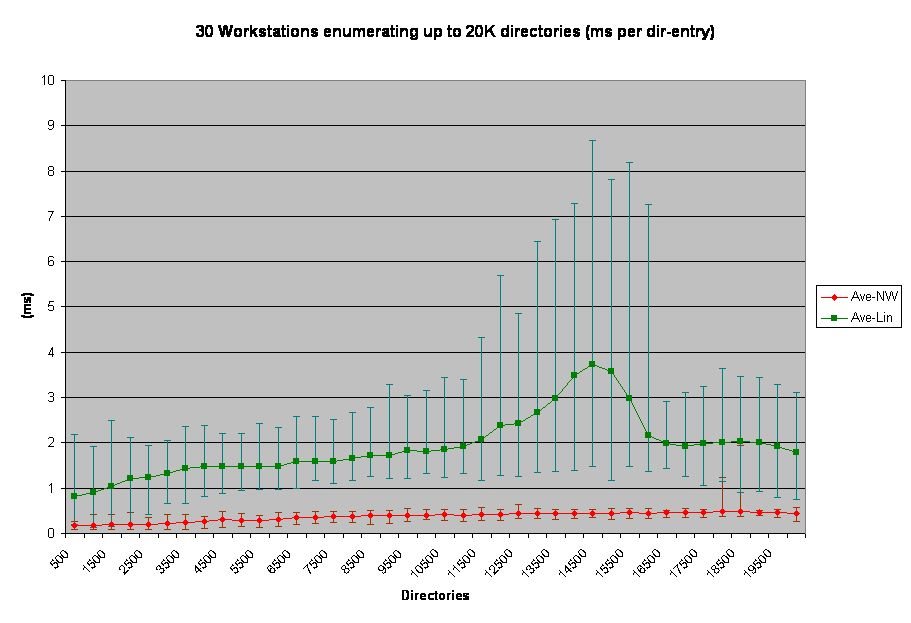
This chart is interesting in several ways. First of all, note the lower error bars for the Linux line. Those bars overlap and up to about 4000 files actually is below the NetWare average. This says to me that when there is CPU room, Linux may be faster than NetWare when responding to file creates. This particular line was caused by the same method as the previous test, namely that some test stations started up to 30 seconds before the whole group was running and therefore had a window of uncontended I/O. Those same workstations finished their tests while others were still around 12000 files, which further explains the downward trend of the Linux line above that threshold. This graph shows significant differences between the two platforms. As with the first chart, 4000 directories and under some workstations turned in NetWare-equivalent response times when speaking to OES-Linux. As with the above, this was due to uncontended I/O. But once all the clients started running the test the response time for directory enumeration was greatly degraded.
This graph shows significant differences between the two platforms. As with the first chart, 4000 directories and under some workstations turned in NetWare-equivalent response times when speaking to OES-Linux. As with the above, this was due to uncontended I/O. But once all the clients started running the test the response time for directory enumeration was greatly degraded.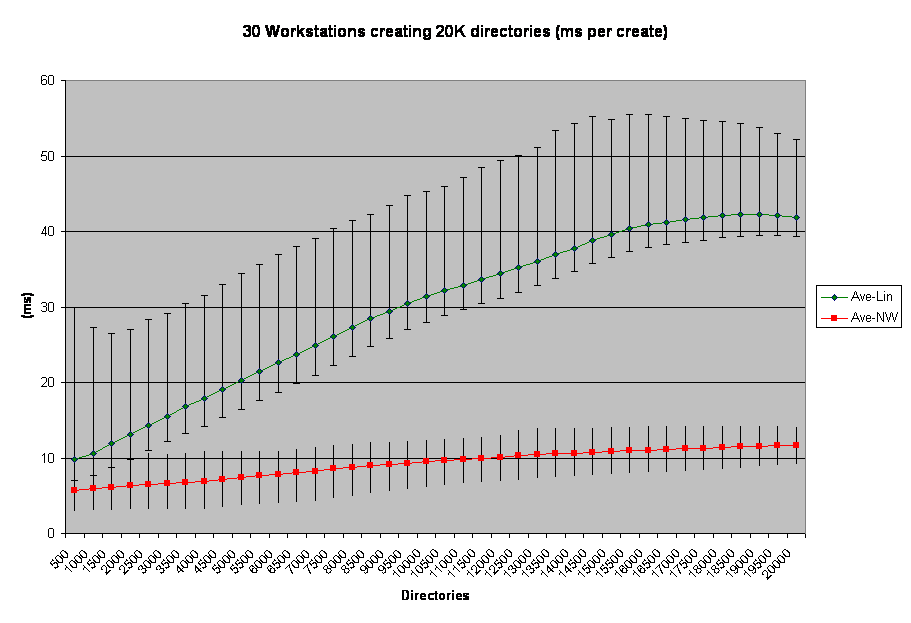
{kind=link}
{kind=link}
{kind=link}